谷歌Genie爆打Sora,基础世界模型AGI来了?一张草图即生一个世界,通才智能体迎来新革命

【导读】真正的「基础世界模型」诞生了!谷歌团队发布110亿参数Genie「精灵」,从一张图片就能创造出可玩的虚拟世界,动作可控碾压Sora。网友惊叹,AI已经杀到视频游戏领域了。
谷歌DeepMind重磅发布了一个基础世界模型——Genie「精灵」。
从一个图像,一张照片,一个草图中,它就能生成一个无穷无尽的世界。

当红炸子鸡Sora虽然创造了令人惊叹的场景,但它们的动作并非可控。
而Genie将成为游戏规则的改变者,创造的虚拟场景可以像电子游戏一样进行互动。

论文地址:https://arxiv.org/abs/2301.07608
Genie的疯狂之处在于,学习了20万小时的未标注互联网视频,无需监督即可训练。
无需任何动作标注,便可以确定谁是主角,并让用户能够在生成的世界中对其控制。

凭借110亿参数,Genie确立了自己作为基础世界模型的地位
具体来说,它是通过潜动作(latent action)模型、视频分词器,以及自回归动态模型三大核心组件来实现的。

由此产生的学习潜动作空间,不仅使用户交互成为可能,而且还有助于训练智能体模仿看不见的视频中的行为。
因此,Genie为培养未来的通才智能体开辟了崭新的途径,重塑了交互式生成环境的格局。
 所以,谷歌DeepMind会用「精灵」为虚拟世界的创建,带来一场新的革命吗?
所以,谷歌DeepMind会用「精灵」为虚拟世界的创建,带来一场新的革命吗? 
AI视频游戏要变天了!
令人惊叹的是,Genie创造一个全新的交互环境只需要一张图像,恰恰为进入虚拟世界开辟了新的途径。
通过最先进的文本到图像生成模型来制作起始帧,然后通过Genie让它们「活」起来。
而且,甚至可以将Genie应用到人类设计的草图或现实世界的图像上!
Genie团队的负责人Tim Rocktäschel称,「Genie作为世界模型,是人类迈向AGI的旅途中非常重要的一步。」
 正如LeCun所说,世界模型需要「动作」。Genie是一个动作可控的世界模型,但完全是通过无监督的视频训练出来的。
正如LeCun所说,世界模型需要「动作」。Genie是一个动作可控的世界模型,但完全是通过无监督的视频训练出来的。  论文作者Jeff Clune称,「任何人,包括孩子,都可以画一个世界,然后『走进它』并探索它」!
论文作者Jeff Clune称,「任何人,包括孩子,都可以画一个世界,然后『走进它』并探索它」!  他把孩子们的画作输入Genie,然后就看到老鹰在空中飞来飞去了。
他把孩子们的画作输入Genie,然后就看到老鹰在空中飞来飞去了。 
 英伟达科学家Jim Fan表示,与Sora不同,Genie实际上是一个由行动驱动的世界模型,具有推断行动的能力。2024年也将是「基础世界模型」年!
英伟达科学家Jim Fan表示,与Sora不同,Genie实际上是一个由行动驱动的世界模型,具有推断行动的能力。2024年也将是「基础世界模型」年!  「Genie是令人疯狂的视频游戏生成器」。
「Genie是令人疯狂的视频游戏生成器」。  也有网友认为,谷歌DeepMind的Genie对视频游戏来说比Sora更重要。
也有网友认为,谷歌DeepMind的Genie对视频游戏来说比Sora更重要。  它是一个基础世界模型,从未标记的互联网视频中训练而来,可以在图像提示下生成无数种动作可控的虚拟世界(即交互式视频游戏)。
它是一个基础世界模型,从未标记的互联网视频中训练而来,可以在图像提示下生成无数种动作可控的虚拟世界(即交互式视频游戏)。  「鉴于DeepMind和OpenAI在游戏引擎方面的悠久历史,我敢打赌,Sora/ChatGPT时刻很快就会在视频游戏中到来」。
「鉴于DeepMind和OpenAI在游戏引擎方面的悠久历史,我敢打赌,Sora/ChatGPT时刻很快就会在视频游戏中到来」。 
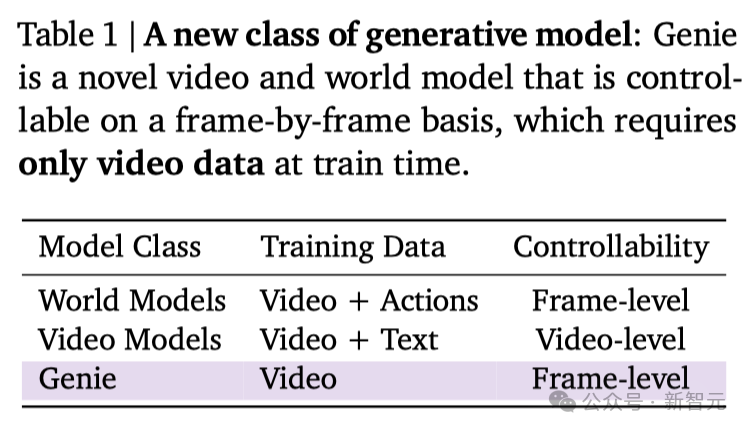
构建交互世界的基础模型
Genie是一种全新的生成式AI范式,仅凭一张图像,就能创造出互动性强、可玩的环境。
Genie能将从未见过的图像作为提示,起到一个世界基础模型的作用——无论是现实世界的照片还是简单的草图,都能让人们与自己幻想中的虚拟世界进行互动。
而且,这一切都在没有任何动作标注的情况下实现的。
Genie所展示的惊人突破,是通过分析超过200,000小时的公开互联网游戏视频学习而来的,主要包括2D平台游戏和机器人领域的视频。
理论上,这个方法可以适用于任何领域,并且能够处理越来越大的互联网数据集。

Genie的独特之处在于,它能够仅通过观看互联网上的视频,就学会对细节进行精确控制。
这项技术面临着不小的挑战,因为网络视频往往缺乏动作标注,甚至不明确指出图像中哪些部分可以被操作。
然而,Genie不仅能识别出哪些图像元素是可控的,还能够洞察到各种隐含的动作,并确保这些动作在它创造的不同环境中保持一致。
值得一提的是,即使是在不同的图像提示下,相同的latent action也会引发相似的行为表现。

为全能AI智能体铺平道路
Genie不仅是一个创新工具,它还为培养能够适应多种环境的AI智能体提供了新的可能性。
过去的研究已经证明,使用游戏环境可以有效地开发AI智能体,但通常当时能用的游戏数量有限。

论文地址:https://arxiv.org/abs/2301.07608
相比之下,Genie学会的动作是可以被应用到真实世界中去的。
借此,我们便能够让未来的AI智能体在一个不断扩展的新世界中进行训练。
生成式虚拟世界的新未来
谷歌称,虽然Genie目前的展示主要在游戏上,但其未来应用远不止于此。
它是一个通用的工具,能够跨越多个领域,而且不需要额外的专业知识就能使用。
就比如,在机器人领域,Genie模型能够让其处理现实世界中的一些任务。
研究人员使用来自RT1的无动作视频训练了一个较小的2.5B模型。
正如在平台游戏中所见,相同动作序列的行为轨迹,通常会表现出相似的模式。
这意味着Genie能够掌握一组统一的动作模式,这对于训练能够在现实世界中灵活应对各种情境的AI智能体来说,具有重要意义。
Genie还能够模拟可变形物体,这是一个对传统由人设计的模拟器来说颇具挑战的任务,但Genie能够通过分析数据学会如何做到这一点。

Genie的诞生,开启了一个全新的时代,让我们能够仅凭图像或文字创造出完整的可交互世界。
谷歌坚信,它将成为推动未来全能AI智能体成长的关键力量。
实现方法
Genie架构中的关键组件是基于视觉Transformer(ViT)。
值得注意的是,Transformer的二次方内存成本对于视频来说是一个挑战,因为视频中可以包含多达 𝑂(10^4) 个token。
因此,研究人员采用了一个内存高效的ST-transformer架构(见图4),在所有模型组件中平衡模型容量与计算限制。
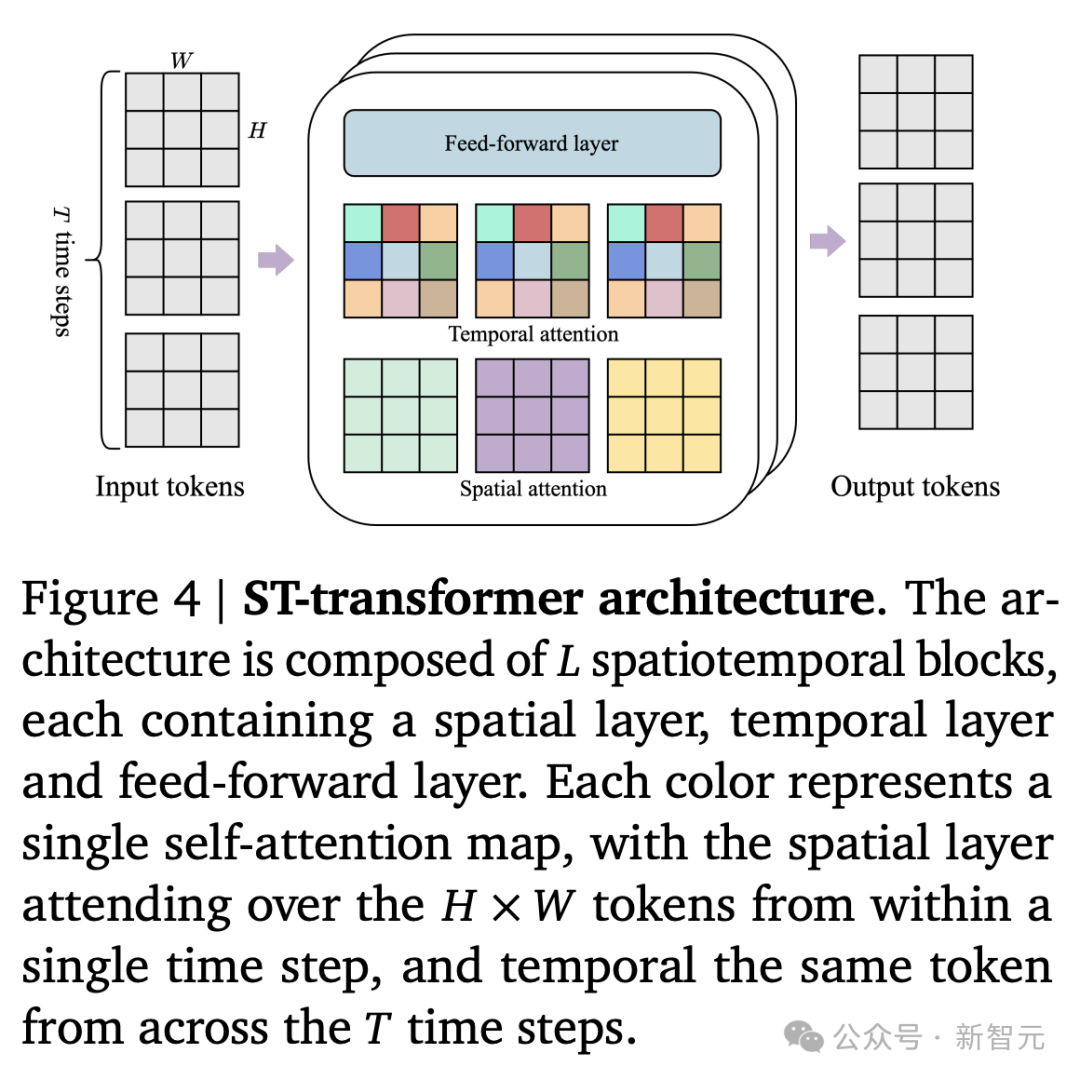
与传统的Transformer不同,其中每个token都关注所有其他token,一个ST-transformer包含𝐿个时空块,其中交错有空间和时间注意力层,之后是一个标准注意力块的前馈层(FFW)。
空间层中的自注意力关注每个时间步内的1 × 𝐻 × 𝑊个token,而时间层关注𝑇 × 1 × 1个token跨越𝑇个时间步。
与序列Transformer类似,时间层假设一个因果结构,带有一个因果掩码。
更关键的是,Genie架构中计算复杂度的主导因素(即空间注意力层)与帧数的增长,呈线性关系而非二次方关系。
这使得它对于视频生成变得更加高效,能够在延长的交互中保持一致的动态。
此外,注意在ST块中,研究人员在空间和时间组件之后只包含一个FFW,省略了空间后的FFW,以便扩展模型的其他组件,并观察到显著提高了性能。
如图3所示,Genie模型包含了三个关键组件:
1) 潜动作模型(LAM),用于分析每两帧之间可能发生的动作𝒂
2) 视频分词器,将视频的每一帧转换为一系列的离散符号𝒛
3) 动态预测模型,根据之前的动作和帧token来预测视频的下一帧内容
研究人员采用了一个分阶段的训练方法,首先训练视频转换器,然后再同时训练潜在动作模型(直接基于视频像素)和动态预测模型(基于转换后的视频token)。
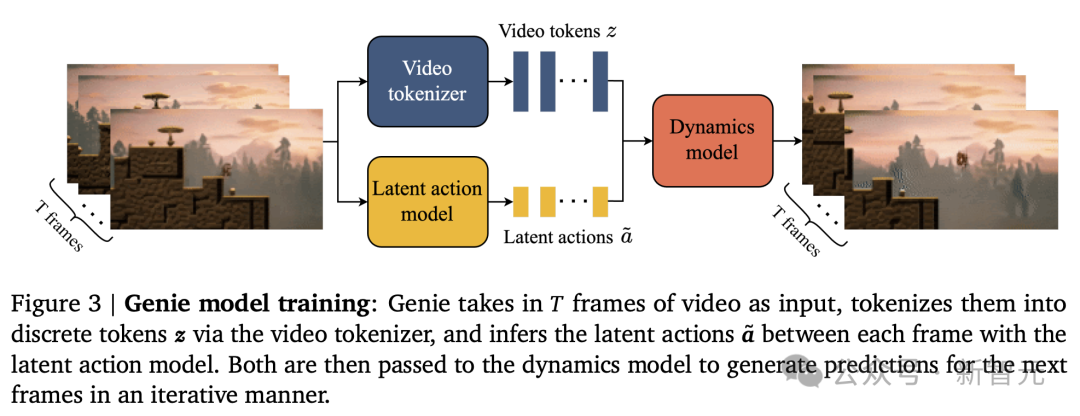
潜动作模型
对于潜动作模型(LAM),作者的目标是能够控制视频内容的生成,即通过预测每一帧之后发生的动作来,生成未来的视频帧。
但是,这样的动作信息在网络视频中很难直接获取,而且标注动作的成本也非常高。
因此,研究人员采用了一种完全无监督的学习方法,来识别这些潜在的动作(如图5所示)。
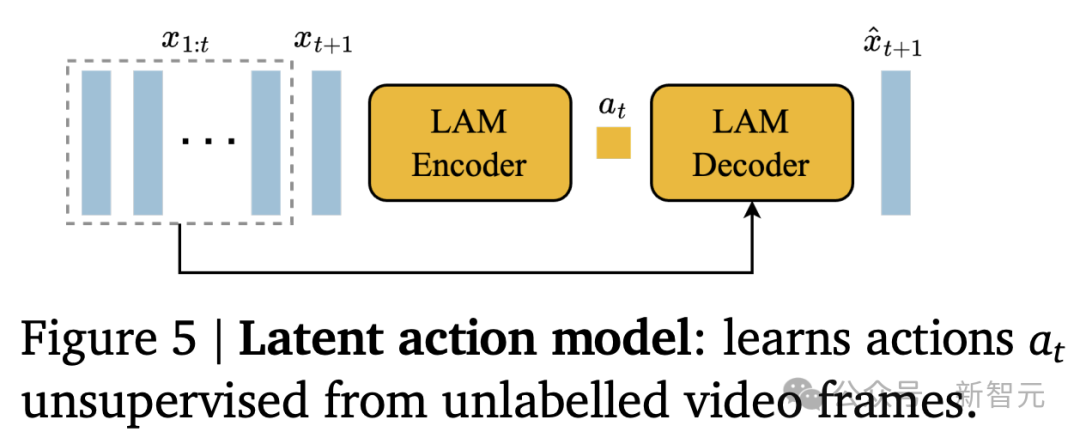
视频分词器
研究人员将视频压缩为离散token,以降低维度并实现更高质量的视频生成(见图6)。
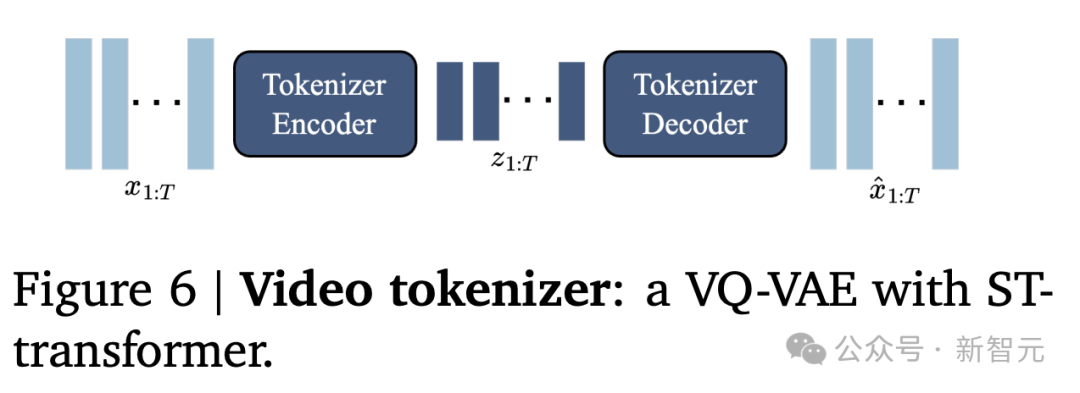
动态预测模型
动态预测模型是一个仅解码器的MaskGIT的Transformer(图7所示)。
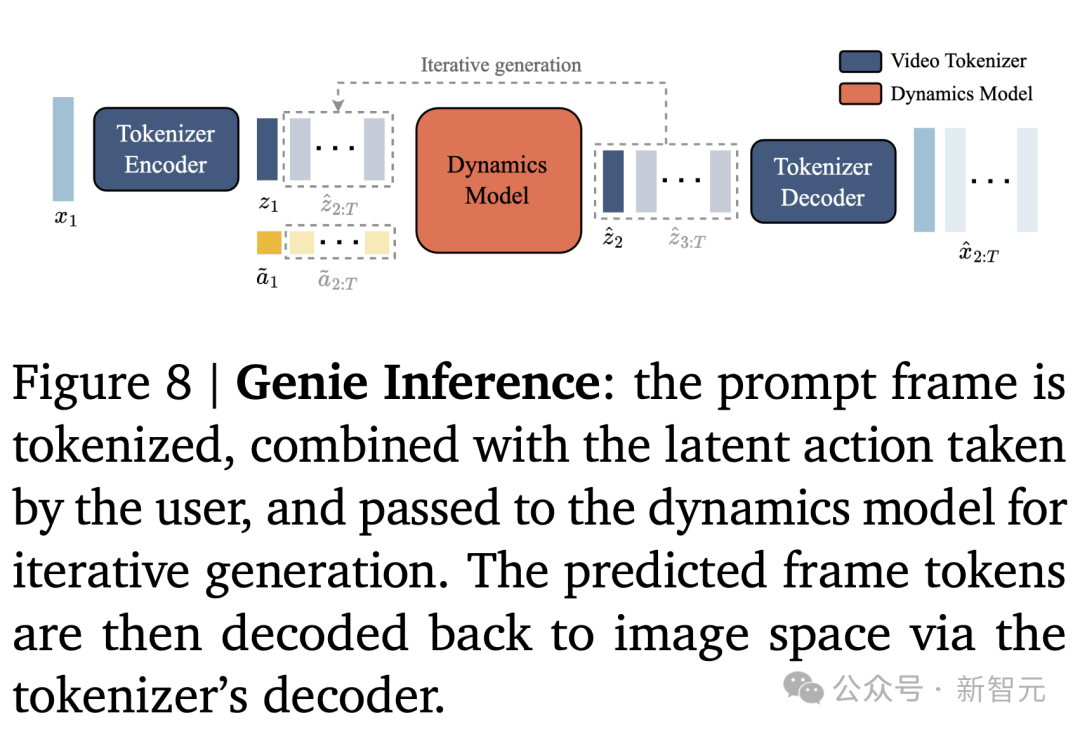
推理:动作可控视频生成
如何使用Genie在推理时,生成动作可控的视频(见图8)。
用户首先用图像𝑥1(作为初始帧)来提示模型。使用视频编码器对图像进行标记,得到𝑧1。然后通过选择[0, |𝐴|]内的任意整数,来指定要采取的离散潜在动作𝑎1。

实验结果
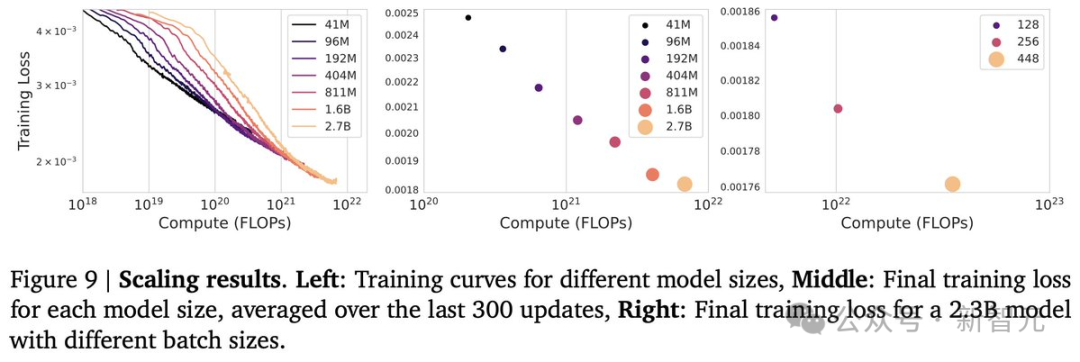
模型缩放
研究人员开发了一个分类器来筛选高质量的视频子集,并通过规模化实验发现,随着模型参数和批大小的增加,模型的性能也会稳步提升。
因此,对于最终模型,研究人员使用256个TPUv5p训练批大小为512的动态模型,总共125k个步骤。
与分词器和动作模型结合使用时,参数总数达到10.7B,并在942B个token上进行训练。
最终得到了,有11B参数的模型Genie。
这里的关键在于数据和算力!
定性结果
平台训练模型
图10显示了由OOD图像提示Genie生成的示例,包括(第一行)从Imagen2生成的图像,(第二行)手绘草图和(第三行)真实照片。
Genie能够将这些想象的世界变为现实,因为我们在与每个例子互动时都能看到类似游戏的行为。

Genie模型的另一新能力便是理解3D场景和模拟视差,这在平台游戏中很常见。
在图12中,研究人员显示了Imagen2生成的图像,其中采取潜在动作以不同的速率将前景移动到背景(如不同颜色箭头的长度所示)。

机器人训练模型
研究人员还发现,Genie可以成功地从视频数据中学习了不同且一致的动作,既不需要文本也不需要动作标记。
 值得注意的是,模型不仅学习机械臂的控制,还学习了各种物体的相互作用和变形物体。
值得注意的是,模型不仅学习机械臂的控制,还学习了各种物体的相互作用和变形物体。 
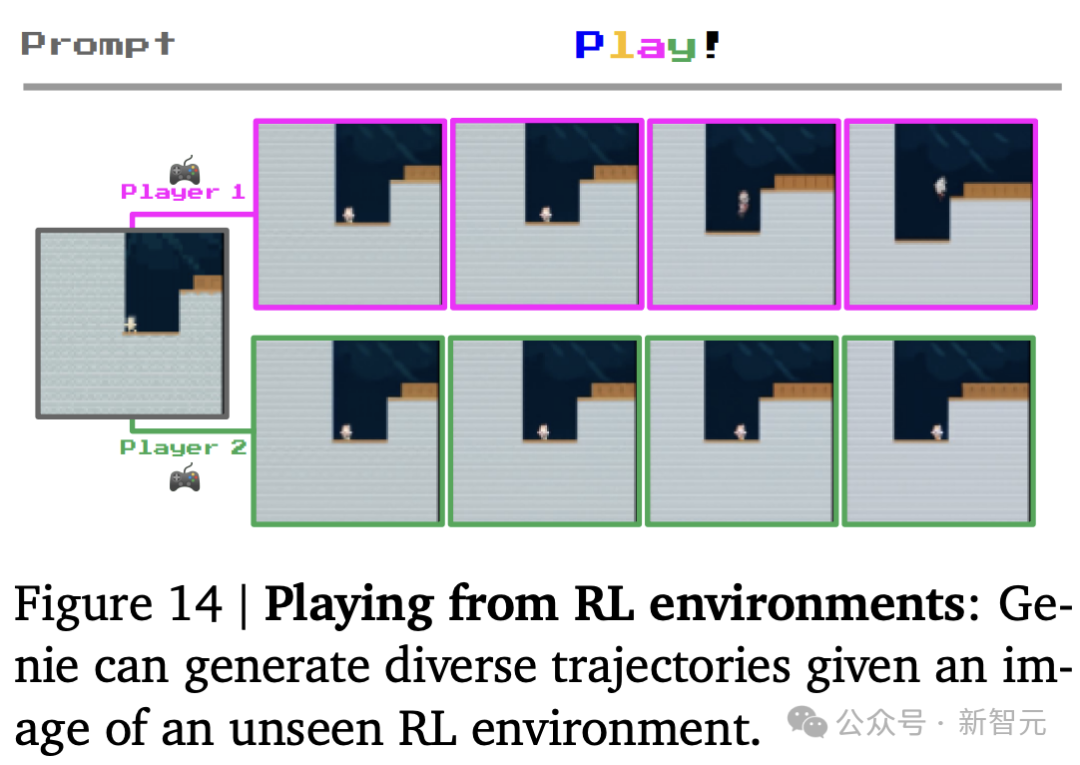
训练智能体
研究人员相信,Genie有朝一日可以用作训练多面手智能体的基础世界模型。
在图14中,他们展示了该模型,已经可以用于在给定起始帧的未见过的RL环境中生成不同的轨迹。
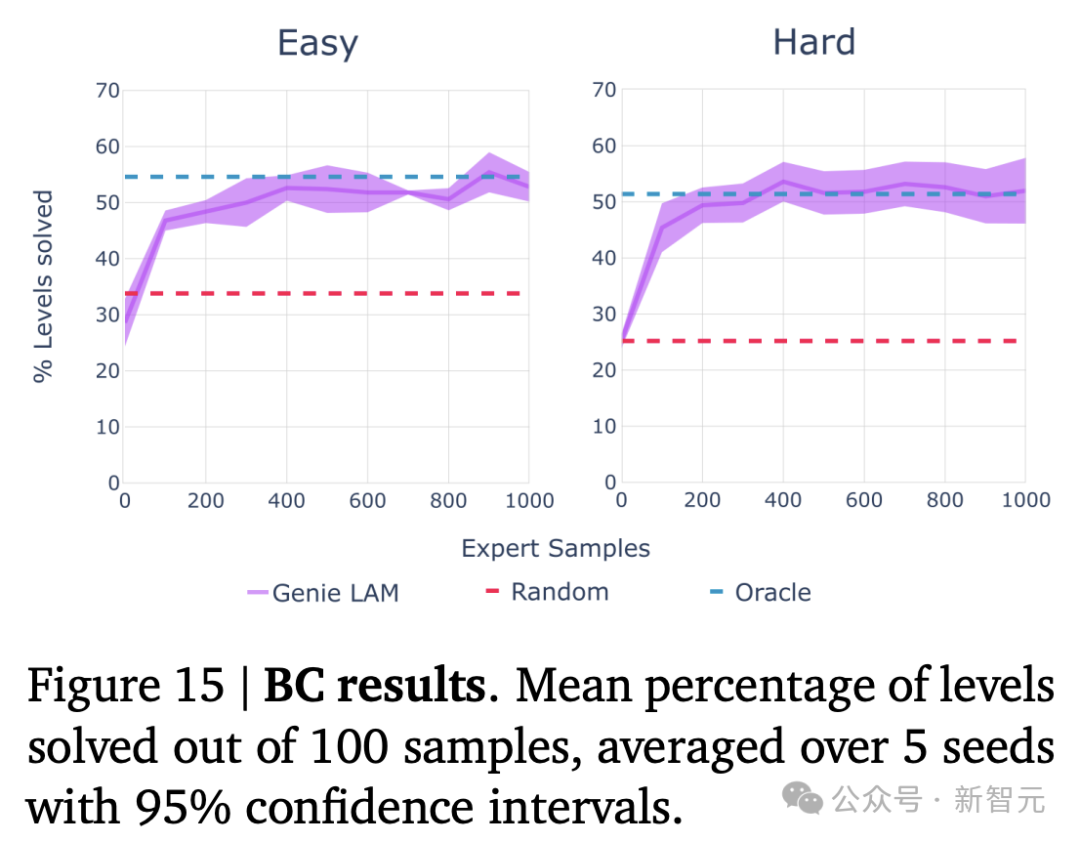
研究人员还在一个程序化生成的 2D 平台游戏环境的难易设置中进行了评估,并将其与oracle行为克隆模型(BC)进行了比较(图15)。
在只有200个专家样本的情况下,基于LAM的策略获得了与Oracle相同的分数,尽管几乎可以肯定的是,CoinRun以前从未见过。
这证明了所学的潜在行动是一致的,并且对转移有实际意义,因为从潜在行动到实际行动的映射,不包含任何有关当前观察的信息。
消融研究
潜在动作模型的设计选择
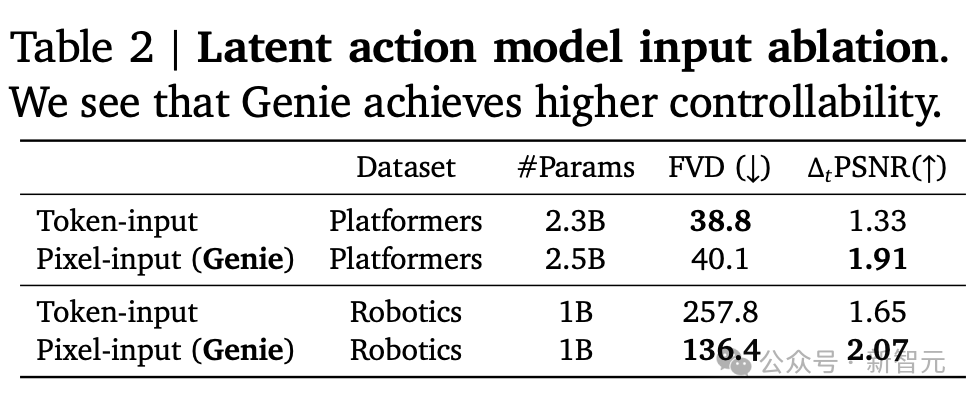
在潜在动作模型输入的消融的研究中,可以看到Genie实现了更高的可控性。
分词器架构消融
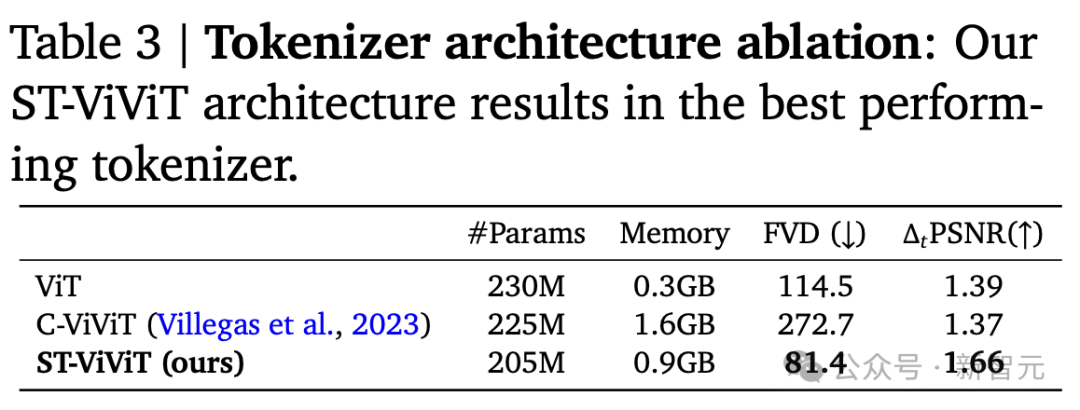
研究人员的ST-ViViT架构成为性能最佳的分词器。
团队介绍
Yuge (Jimmy) Shi

Yuge (Jimmy) Shi曾是牛津大学Torr Vision Group的机器学习博士生,导师是Philip Torr。毕业后,入职谷歌成为一名研究科学家。
在此之前,她还在澳大利亚国立大学获得了工程学学士学位。
详细的团队成员和贡献如下:

转载请注明:谷歌Genie爆打Sora,基础世界模型AGI来了?一张草图即生一个世界,通才智能体迎来新革命 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号