LeCun又双叒唱衰自回归LLM:GPT-4的推理能力非常有限,有两篇论文为证
「任何认为自动回归式 LLM 已经接近人类水平的 AI,或者仅仅需要扩大规模就能达到人类水平的人,都必须读一读这个。AR-LLM 的推理和规划能力非常有限,要解决这个问题,并不是把它们变大、用更多数据进行训练就能解决的。」


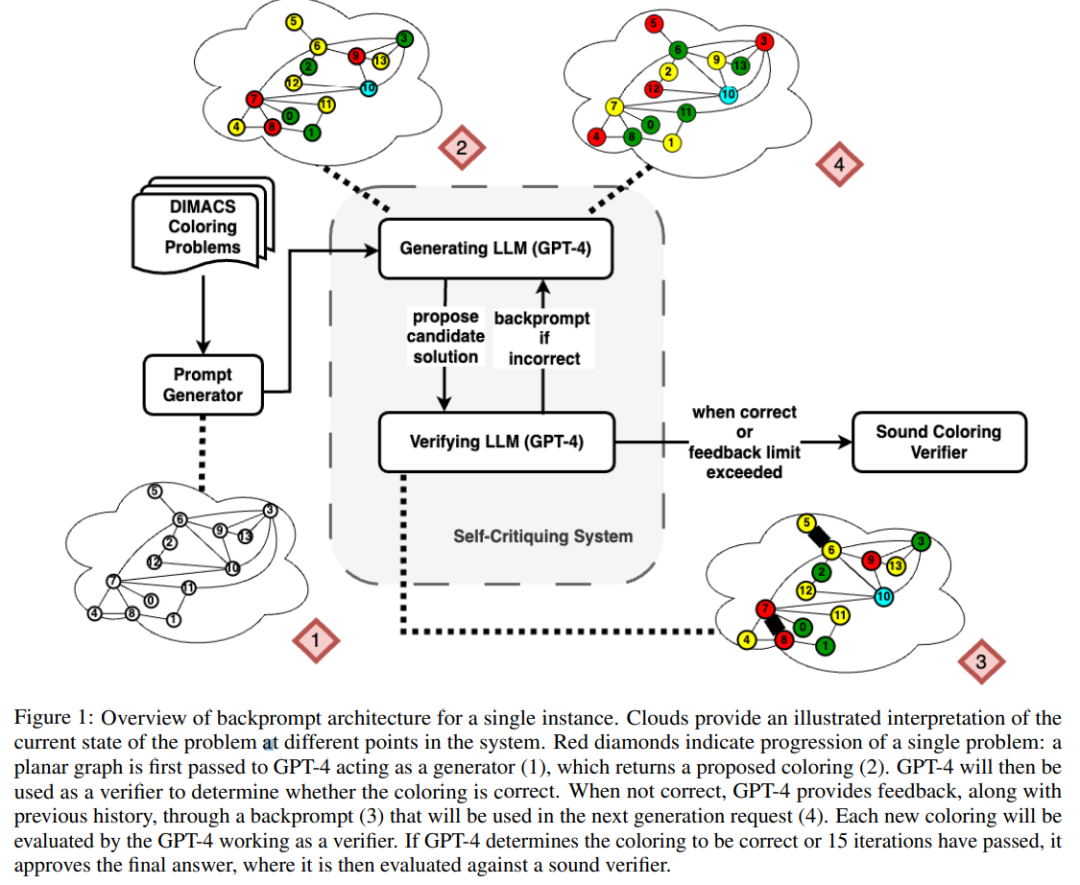
 即使 GPT-4 偶然猜出了一个有效的颜色,它的自我批判可能会让它产生幻觉,认为不存在违规行为。
即使 GPT-4 偶然猜出了一个有效的颜色,它的自我批判可能会让它产生幻觉,认为不存在违规行为。 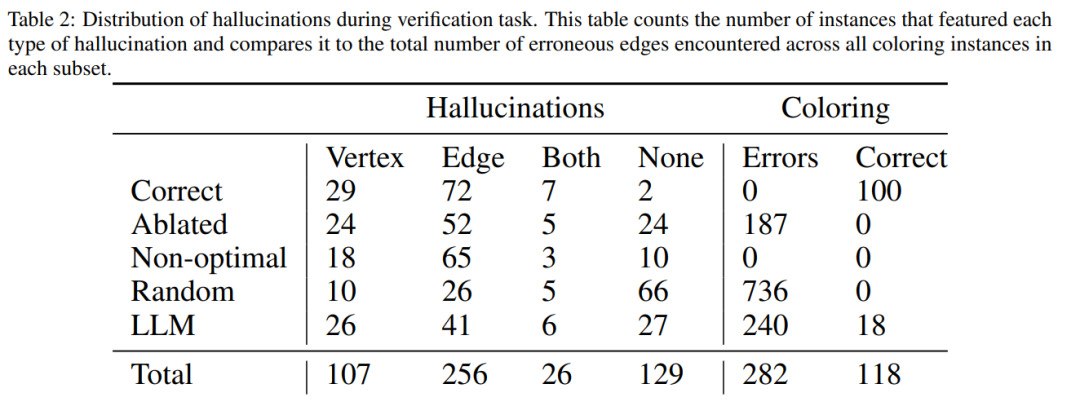
-
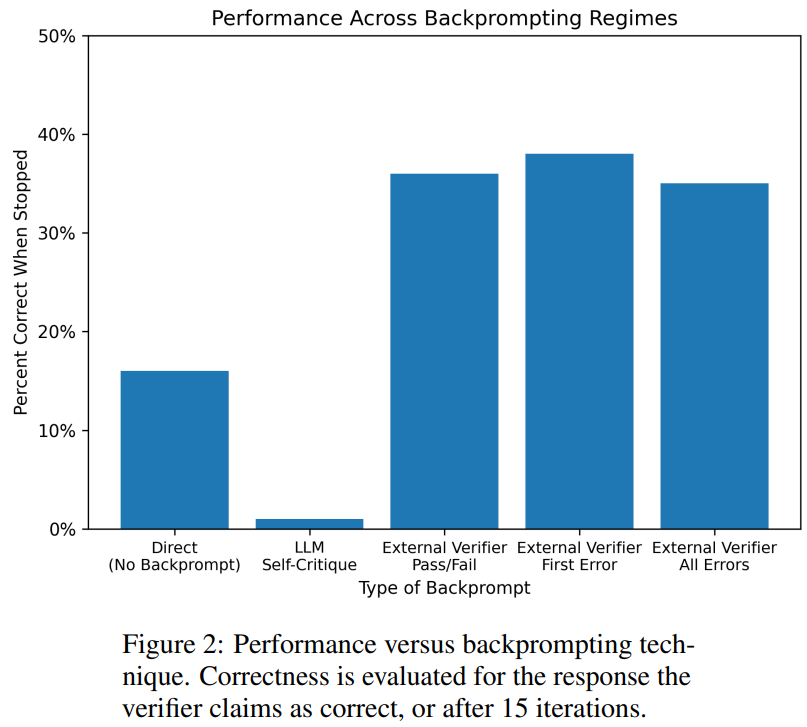
自我批判实际上会损害 LLM 的性能,因为 GPT-4 在验证方面很糟糕; -
来自外部验证器的反馈确实能提高 LLM 的性能。

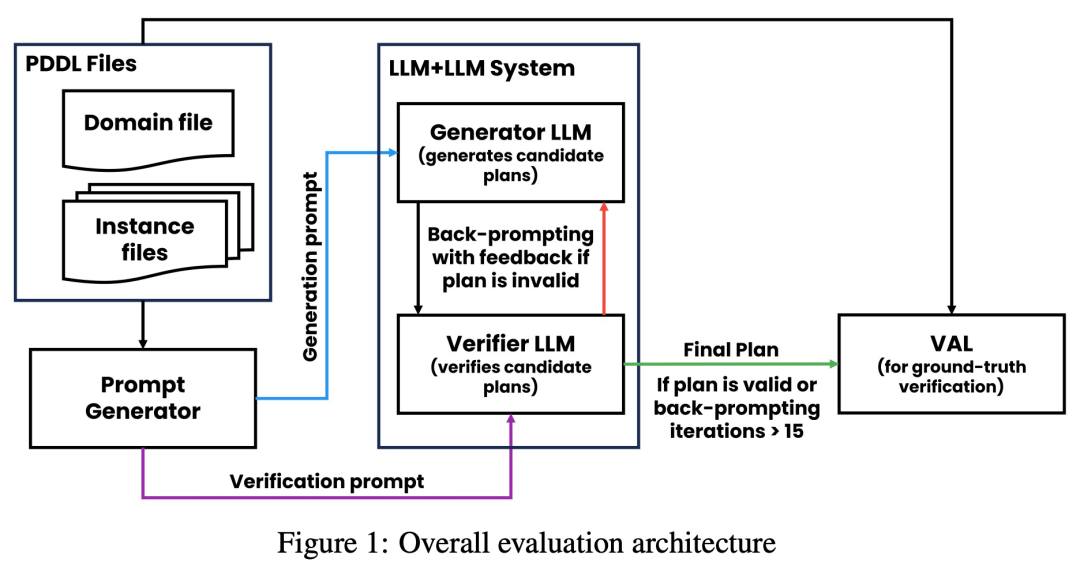
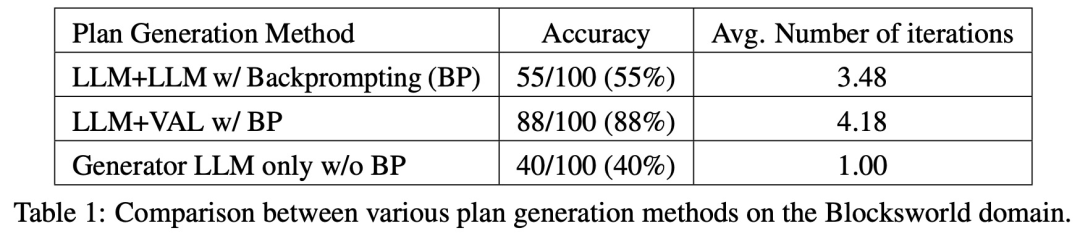 在 100 个实例中,验证器准确识别了 61 个(61%)。
在 100 个实例中,验证器准确识别了 61 个(61%)。 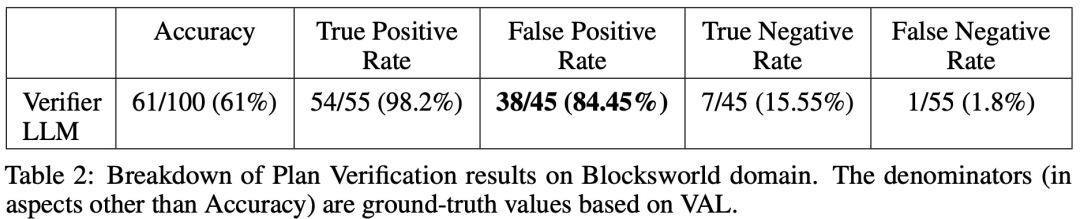 下表显示了 LLM 在接受不同级别反馈(包括没有反馈)时的表现。
下表显示了 LLM 在接受不同级别反馈(包括没有反馈)时的表现。 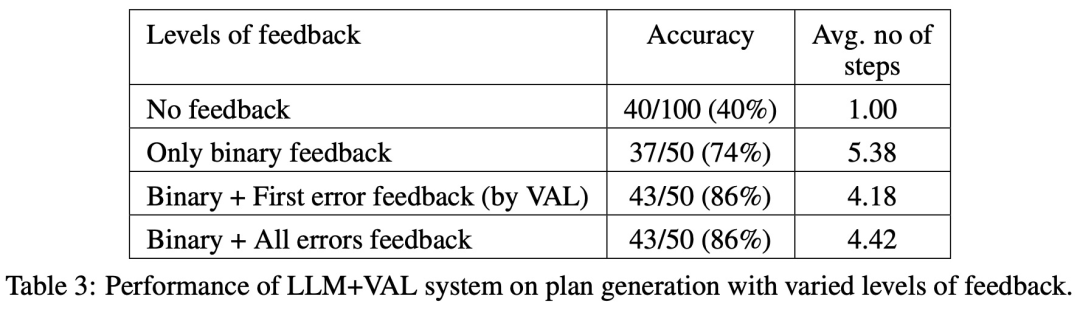
文章来源:https://mp.weixin.qq.com/s/osHH3wkPvSw2eZvNQO8Pzg
版权声明:MM 发表于 2023-10-25 2:28 PM。
转载请注明:LeCun又双叒唱衰自回归LLM:GPT-4的推理能力非常有限,有两篇论文为证 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
转载请注明:LeCun又双叒唱衰自回归LLM:GPT-4的推理能力非常有限,有两篇论文为证 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章
GO123.AI网址大全是猎户星空旗下的一款收集流行AI应用网址的平台,提供AI作图、聊天、视频编辑等资源。我们还提供ChatGPT的新手教程和高级玩法指导,为用户提供最全面、最实用的服务。欢迎来猎户星空旗下的GO123.AI网址大全,一起探索AI应用的无限可能!

 京公网安备 11010502044423号
京公网安备 11010502044423号