深度生成模型
目前主流的深度生成式模型目前有三种:
1.变分自编码VAE : 采用的是先编码,引入高斯噪音,再进行解码,并希望解码器的输出和目标样本的分布越相近越好。 VAE2.对抗生成模型GAN : 采用的是先编码,再进行解码,并引入一个判别器去判断解码生成器生成的样本是否符合目标分布。GAN扩散模型Diffusion:通过扩散步骤,将目标分布的样本扩散到一个高斯分布,然后采用逆扩散将一个高斯随机噪声还原到目标分布。Diffusion
而其中Diffusion模型是再数学上有着比较深的学问,笔者还不甚了解。这里就不过多介绍,说明一点,目前上述三类型生成模型当中,Diffusion模型的生成效果最好,也是目前市面上很多效果很惊人的的AI作画师的底层算法。
stable diffusion
stable diffusion是一种 conditional Diffusion模型,从下方模型架构图可以简单的看到,其主要是在逆扩散 生成图片的过程中 加入 文本 特征,引导逆扩散的生成的过程,生成你想要的图片。
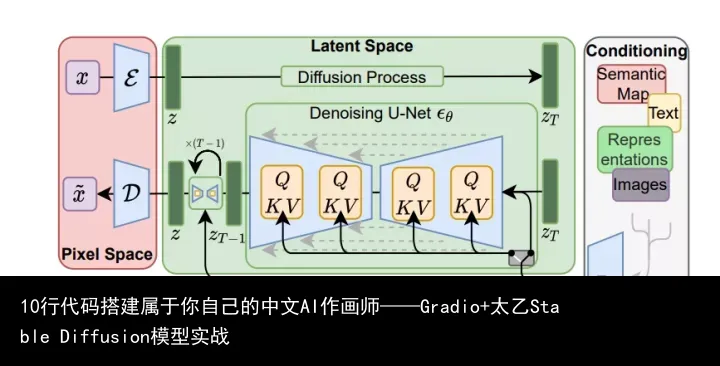
stable diffusion
Gradio
Gradio 号称3行代码就可以搭建一个AI模型的demo,这使得AI算法工程师可以极其方便的通过web网页分享自己的模型,供别人使用。这里是Gradio官网地址https://gradio.app/。笔者使用了一下,确实只需要很少的代码就能搭建了一个AI模型的demo,省去了大量的后端以及前端代码编写。
太乙中文stable-diffusion 图片生成模型
太乙中文 stable-diffusion 图片生成模型是IDEA-CCNL组织开源的一个太乙多模态模型簇中的一个,主要是将stable-diffusion模型中文化,让大家可以用中文进行AI作画。太乙其实还有中文CLIP模型 ,笔者也曾写过太乙CLIP实战教程。 IDEA-CCNL组织开源了很多封神宇宙得预训练模型,非常的强大,造福了大批我们这种GPU-poor 玩家。其中太乙中文stable-diffusion效果如下,看起来画的还是很逼真。

太乙的效果
AI作画师demo实战部分
1.首先通过你需要安装两个python 包:diffusers ,gradio。我们需要difusers去加载太乙中文stable-diffusion 图片生成模型,然后进行图片生成。 2.去huggface网站中下载太乙中文stable-diffusion 图片生成模型,链接如下,https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1。 或者直接运行下方命令进行模型下载。
git clone https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
3.将模型放到项目目录下,然后编写Artists.py代码

项目目录
Artists.py代码的内容如下:其实就是采用gradio 的Intereface 将 加载了太乙中文stable-diffusion 图片生成模型 的 DiffusionPipeline 直接服务化。
import gradio as grpipeline = DiffusionPipeline.from_pretrained("./Taiyi-Stable-Diffusion-1B-Chinese-v0.1")
def generate(text, steps):
image = pipeline(text,
num_inference_steps=steps,
guidance_scale=7.5).images[0]
return image
if __name__ == __main__:
demo = gr.Interface(title="太乙中文 stable diffusion 模型",
css="",
fn=generate,
inputs=[gr.Textbox(lines=3, placeholder="输入你想生成的图片描述", label="prompt"), gr.Slider(0, 100)],
outputs=[gr.outputs.Image(label="图片")])
demo.launch()
运行代码会在本地 http://127.0.0.1:7860/ 上起一个web服务
后台日志 4. 通过web进入服务后,UI界面如下图所示:一个文本输入框;一个step的输入Slider,step设置的越大耗时越长,图片效果越好。一个图片输出框。
输入你想生成的图片描述,设置好step步数,即可开始作画。
这里笔者输入参数的是 prompt :一行白鹭上青天; step:20 。
意思是: 随机采样后 采用diffusion 模型逆扩散20步生成 符合 一行白鹭上青天语义的图片。 CPU机器上扩散20个step,大约耗时5分钟生成结果图,当然如果采用GPU速度会更快。最终结果图片如下:三只白鹭站在河畔的树下,虽然不是100%符合输入描述,但是图片的意境和质量确实不错。
AI作画师web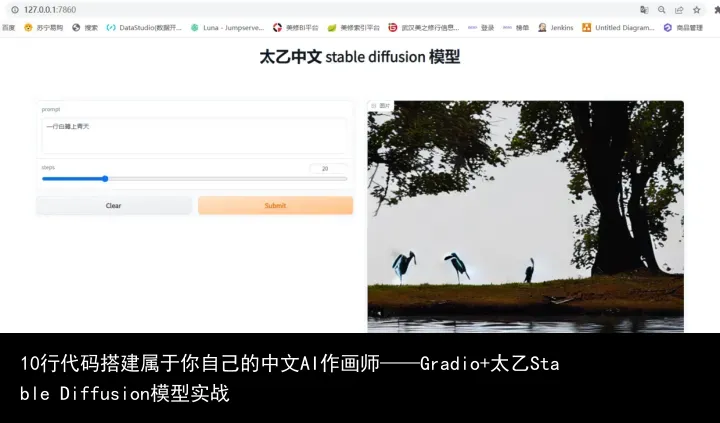 服务
服务
再来一张,一枝红杏出墙来。红杏确实确实很红,但是没有墙。估计模型还需要继续的finetune。才能达到最好的效果。
AI作画师web服务
结语
最终我们通过差不多10行代码(如果不换行的化,哈哈哈),就搭建了一个中文AI作画师的demo,不需要GPU也可作画,非常的方便。目前diffusion 生成的图片效果越来越好,而且,学术界在正在不断研究diffusion 的变种去生成图片,视频,文章,甚至分子结构,蛋白质等。感觉深度生成模型继GAN之后又迎来了一次大的突破,而且diffusion在数学上有着比较完备的原理,这也最有数学性的一个深度模型。不得感叹一句:数学才是硬道理。
引用
https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1 https://mp.weixin.qq.com/s/f9Q7hee9cWIwtKwC5V9Y8w
https://arxiv.org/abs/2112.10752
转载请注明:10行代码搭建属于你自己的中文AI作画师——Gradio+太乙Stable Diffusion模型实战 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号