Stable Diffusion 是由 CompVis、Stability AI 和 LAION 共同开发的一个文本转图像模型,它通过 LAION-5B子集大量的 512x512 图文模型进行训练,我们只要简单的输入一段文本,Stable Diffusion 就可以迅速将其转换为图像,同样我们也可以置入图片或视频,配合文本对其进行处理。先来看几个示例吧。

Prompt: In a cyberpunk city, a police car is on the street, raining, light effect, Simon Stalenhag, Ian McQue, Ghibli Studio, Beeple, Kaino University

Prompt: Glowing crystals in the depths of the black valley, Simon Stalenhag, Ian McQue, Ghibli Studio, Beeple, Kaino University, high-definition picture, unreal engine

Prompt: A silver mech horse running in a dark valley, in the night, Beeple, Kaino University, high-definition picture, unreal engine, cyberpunk

Prompt: An astronaut floating in the universe

Prompt: Grass and flowers by the sea, forest, clear sky, light effect, Beeple, Caspar David Friedrich, Alphonse Mucha

Prompt: Two knife-wielding pirates dueling on a pirate ship, dusk, heavy rain, unreal engine, 8k, high-definition, by Alphonse Mucha and Wayne Barlowe
使用 Stable Diffusion 目前有几种不同的途径:
01. Stable Diffusion Demo,这是官方发布的一个简单的体验版,无需登录,只需要「输入描述文本」,然后点击「生成图像」即可,可进行简单的设置,需要排队,等待时长根据排队人数而定,通常需要几分钟,完成后图片会展示在文本下方,可右击保存,只可生成 512x512 像素的图片。

02. DreamStudio Beta,这是官方发布的公测版,可以对参数进行调整,需要注册登录,注册后会获得 200 积分(generations/credits),每次生成需要消耗相应的积分,积分用完后需要购买才可继续使用,价格 10 英镑(80 元左右)1000 积分。
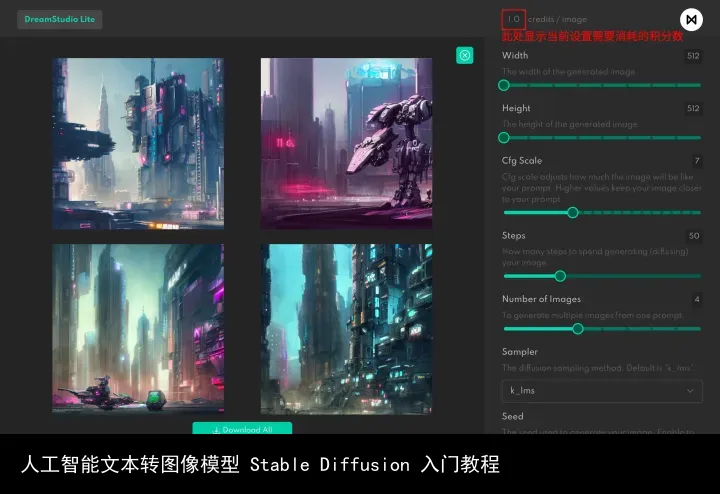
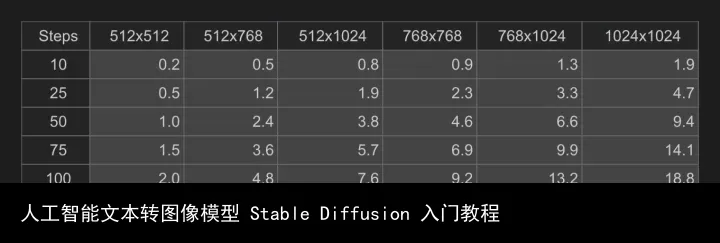
界面右侧是参数调整区,可调整图片的尺寸、文本描述与成图的贴近程度、步数、生成图片的张数、采样模式和种子,一般按默认参数即可,其中图片尺寸和步数会影响消耗的积分数量,步数建议使用默认 50 步,高了也并没有太大区别,各种尺寸和步数需要的积分如下。
图片生成后可点击图片中心的下载按钮下载图片,若生成多张图片可点击图片下方的「Download All」按钮下载全部图片,注意目前生成多张图片时若点击某张图片进行放大预览后是无法返回多图预览界面,无法再下载其他图片的,因此如果生成了多张图片建议先全部下载下来。
点击界面左侧的「History」可进入历史记录页面,可以查看之前生成图片的记录,这里主要记录了历次生成的 Prompt、尺寸和种子等信息,如果想对过去生成的图片进行优化或调整,可在此复制 Seed 值,并回到 Dream 页面打开界面右下角 Random Seed 后方的按钮,然后将种子值粘贴至此,在调整参数或描述,重新生成图片。
点击界面右上角自己的头像,选择「Membership」进入个人中心,可查看个人积分余额及充值。
03. Stable Diffusion ,这是官方发布的 Google Colab 版本,无生成次数限制,需要注册 Hugging Face 账号,需要谷歌账号,需要科学上网,这个版本的流程有点繁琐,不推荐,这边不做介绍了。
04. Stable Diffusion WebUI 1.4,这是由 @altryne 制作的有 WebUI 的 Google Colab 版本,无生成次数限制,需要注册 Hugging Face 账号,需要谷歌账号,需要科学上网,这算是目前比较好用的一版,这边详细介绍一下。
准备工作______________________________________________________________________
04.01. 注册谷歌账号并登录。
04.02. 注册 Hugging Face账号并登录(注册后去邮箱验证一下)。
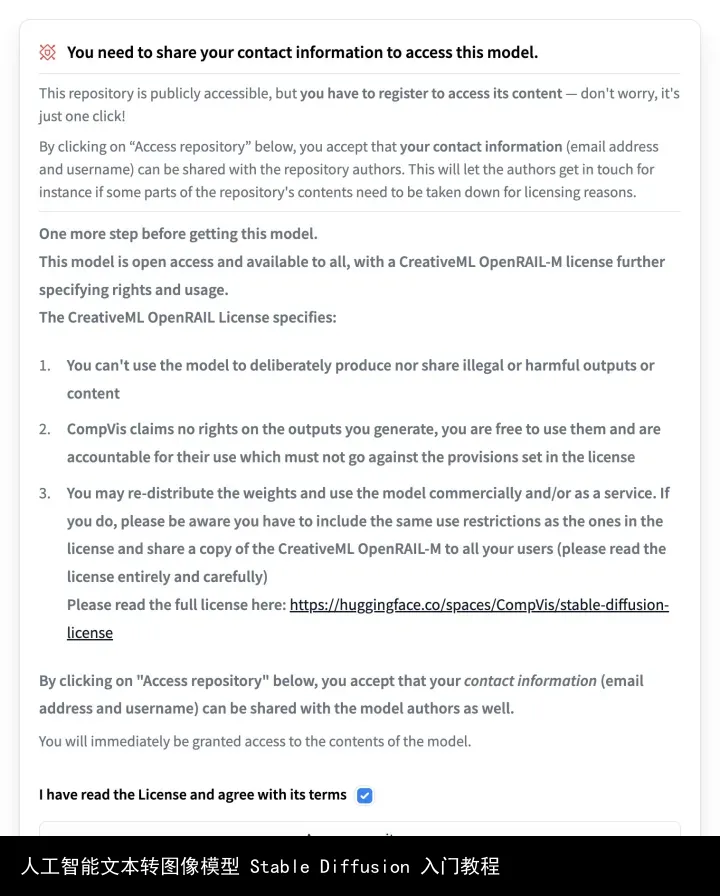
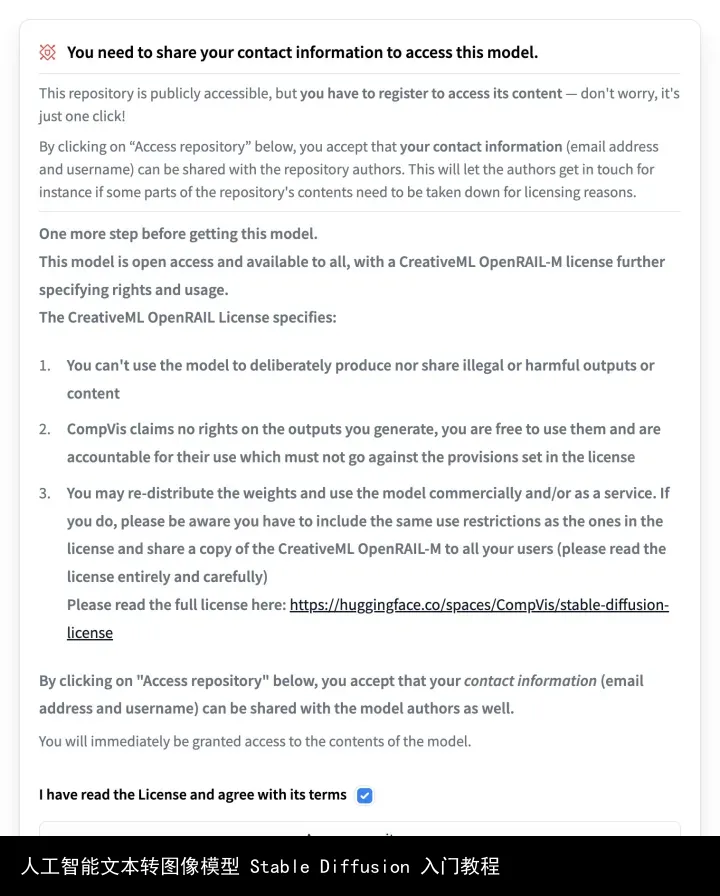
04.03. 打开 CompVis/stable-diffusion-v1-4页面,找到下图部分,勾选同意选项,点击「Access repository」,开通模型访问权限。(这里列出了使用协议,可以自己看一下)
04.04. 打开 CompVis/stable-diffusion页面,找到「stable-diffusion-v-1-4-original」并单击打开链接。(如果以后更新版本了,请打开对应版本的链接)
04.05. 找到下图部分,勾选同意选项,点击「Access repository」,开通模型下载权限。
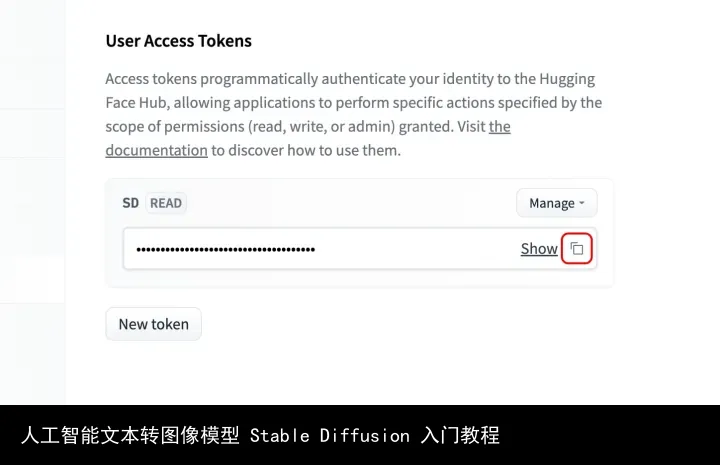
04.06. 打开 Access Tokens页面,点击「New Token」按钮,起个名字,Role 选 read 或者 write 都可以,点击「Generate a token」,点击 Show 后面的复制按钮复制 Token。
入门教程______________________________________________________________________
04.1. 打开 Stable Diffusion WebUI 1.4,若未自动登录谷歌账号请点击页面右上角「登录」按钮,登入你的谷歌账号。
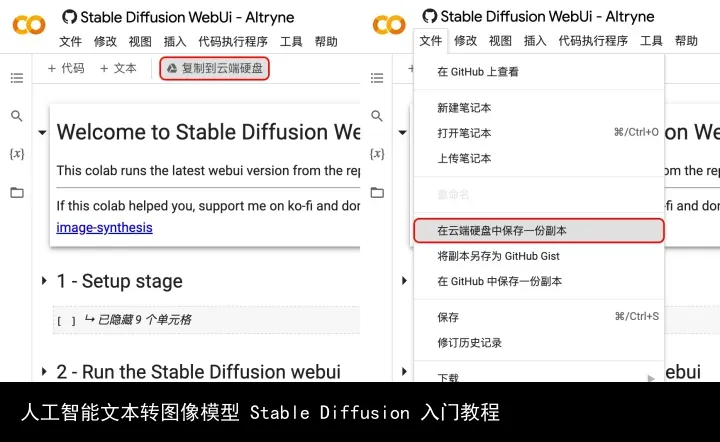
04.2. 点击「复制到云端硬盘」或点击「文件」选择「在云端硬盘中保存一份副本」。
04.3. 副本创建完成会出现「笔记本的副本已完成」弹窗,点击「在新标签页中打开」。
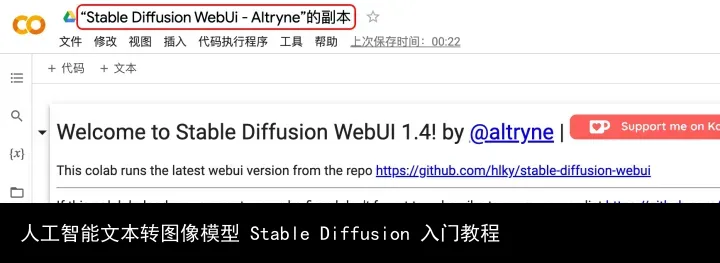
04.4. 点击「“Stable Diffusion WebUi - Altryne”的副本」修改笔记本名称(不改也可以,以后就能直接从自己的云端硬盘打开这个文件运行 Stable Diffusion 了)。
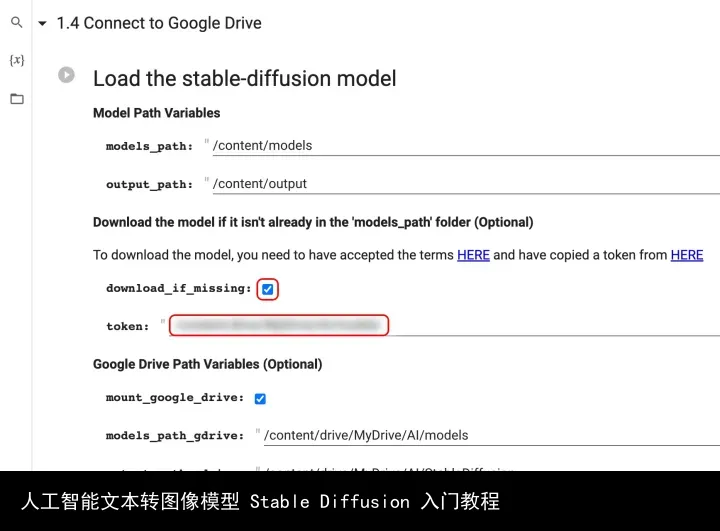
04.5. 点击「1 - Setup stage」前面的小三角,找到「1.4 Connect to Google Drive」,将 token(第 04.06. 步复制的 token)粘贴在图中位置,并勾选「download_if_missing」选项。
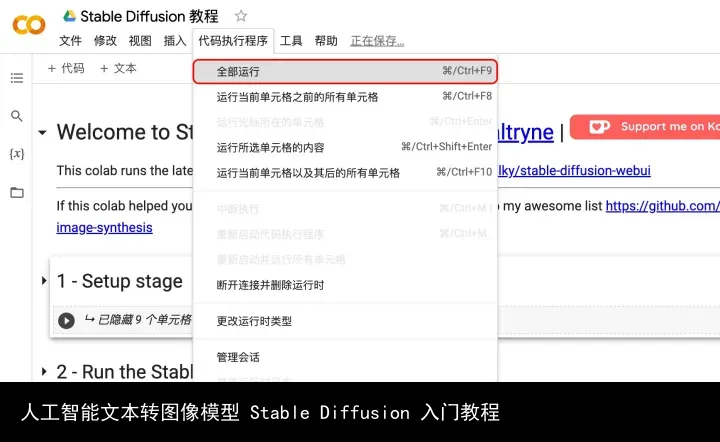
04.6. 点击「代码执行程序」选择「全部运行」。
04.7. 弹出「笔记本需要高 RAM」的窗口,点击「确定」。(接下来需要等待一段时间,你看到 1 - Setup stage 下面的按钮在转圈圈就表示程序正在运行,需要下载一些文件,第一次运行等待时间会稍长一些)
04.8. 弹出「您还在设备面前吗?」的窗口,点击「进行人机身份验证」,按指令进行验证。(如果没有弹出可忽略)
04.9. 弹出「允许此笔记本访问您的 Google 云端硬盘文件吗?」的窗口,点击「连接到 Google 云端硬盘」。
04.10. 弹出「登录 - Google 账号」窗口,选择你的谷歌账号,点击「允许」。(如果等待过程中 Google Colab 图标变红,网络中断,可点击页面右上角的重新连接,重连后会继续运行)
04.11. 点击「3 - Launch WebUI for stable diffusion」前面的小三角展开单元,当这个单元最下方出现「Running on public URL:https://57651.gradio.app」就表示程序启动成功,点击「https://57651.gradio.app」打开 WebUI。(每次会得到不同的地址)
04.12. 在如图位置输入prompt(描述文本),设置好图片尺寸和生成图片张数,其他建议按默认值,点击「Generate」就开始生成了。
04.13. 回到 Stable Diffusion WebUi - Altryne 的页面,你会在「3 - Launch WebUI for stable diffusion」的末尾看到实时进度,以下图为例,Iteration: 1/12 表示总数 12 张图的第 1 张图片,以此类推,前面的 100% 是完成进度,50/50 是当前完成步数/总步数,00:42<00:00 是已使用时间<剩余时间,1.17it/s 是每秒完成 1.17 步,当出现 [MemMon] Stopped recording. 就表示当前任务的所有图片已经生成完毕。(正常情况生成结束后 WebUI 页面也会展示生成的图片,但是如果有网络不稳定、延迟大等情况或者连续运行超过 90 分钟,生成完毕后 WebUI 页面可能不会显示图片,甚至还在继续计时,此时 WebUI 页面已经断开连接,需要刷新页面后恢复使用)
04.14. 现在你就可以在 Google Drive直接查看保存的图片了,打开 AI - StableDiffusion 文件夹,这个文件夹里保存的是每次生成任务的汇总图,如果一次生成了多张图片它会自动把这些图片拼在一起。在「samples」文件夹内会以每次生成任务的 prompt 为名称分别建立子文件夹,生成的图片会保存在里面,并且每张图都会附带一个 yaml 格式的配置文件,可以查看这张图片的参数设置。
进阶教程______________________________________________________________________
04.15. 打开 WebUI 第二个标签,这个是图像转图像,就是添加一张参考图,配合文本描述生成图片,注意参考图的尺寸要和输出尺寸一致,否则会报错,可以将图片调整好尺寸以后再添加进来,或者使用左图下方的「Advanced Editor」编辑图片后再操作,步数建议 50 步,图中两个有说明的值可以调整生成效果,建议在默认值左右小范围调整以观察效果,极端值效果不佳。
04.16. WebUI 第三个标签是人脸修复工具,我试验了效果并不理想,使用方式就是添加图片点生成就行了,这边重点推荐一下第四个标签,RealESRGAN 是一个智能放大图片的模型,效果十分惊人,我之前一直用的是 Topaz Gigapixel AI,RealESRGAN 的效果完爆 Topaz Gigapixel AI,操作也很简单,添加图片点击生成即可,这里有两个模型,有一个模型是动漫专用的。
05. pharmapsychotic Stable Diffusion,这是由 @pharmapsychotic 制作的 Google Colab 版本,无生成次数限制,需要注册 Hugging Face 账号,需要谷歌账号,需要科学上网,这个版本的操作比较接近 Disco Diffusion,DD 玩家用起来可能比较顺手,这边也介绍一下。
准备工作______________________________________________________________________
05.01. 注册谷歌账号并登录。(如果之前使用过 Stable Diffusion WebUI 1.4或其他 Google Colab 版本的 Stable Diffusion 可跳过步骤 05.02.-05.06.)
05.02. 注册 Hugging Face 账号并登录(注册后去邮箱验证一下)。
05.03. 打开 CompVis/stable-diffusion 页面,找到「stable-diffusion-v-1-4-original」并单击打开链接。(目前最新的版本是 1.4,如果以后有更新也可以来这里下载更新的版本)
05.04. 找到下图部分,勾选同意选项,点击「Access repository」,开通模型访问权限。(这里列出了使用协议,可以自己看一下)
05.05. 在页面上找到下图位置,通过链接下载「sd-v1-4.ckpt」文件。
05.06. 打开 Google Drive 并登录你的账号,将下载的「sd-v1-4.ckpt」文件上传至 AI 文件夹内的 models 文件夹内,如果没有这个文件夹请手动新建文件夹。
入门教程______________________________________________________________________
05.1. 打开 pharmapsychotic Stable Diffusion,若未自动登录谷歌账号请点击页面右上角「登录」按钮,登入你的谷歌账号。
05.2. 点击「复制到云端硬盘」或点击「文件」选择「在云端硬盘中保存一份副本」。
05.3. 副本创建完成会出现「笔记本的副本已完成」弹窗,点击「在新标签页中打开」。
05.4. 点击「“pharmapsychotic_Stable_Diffusion.ipynb”的副本」修改笔记本名称(以下所有代码可视为源文件/源代码,此处是源文件的名称,可按创作主题或其他方式命名,方便后期修改和区分)。
05.5. 修改文件夹名称、步数、生成图片张数等参数,输入描述文本。
05.6. 点击「代码执行程序」选择「全部运行」。
05.7. 弹出「笔记本需要高 RAM」的窗口,点击「确定」。(接下来需要等待一段时间,第一次运行等待时间会稍长一些)
05.8. 弹出「您还在设备面前吗?」的窗口,点击「进行人机身份验证」,按指令进行验证。(如果没有弹出可忽略)
05.9. 弹出「允许此笔记本访问您的 Google 云端硬盘文件吗?」的窗口,点击「连接到 Google 云端硬盘」。
05.10. 弹出「登录 - Google 账号」窗口,选择你的谷歌账号,点击「允许」。(如果等待过程中 Google Colab 图标变红,网络中断,可点击页面右上角的重新连接,重连后会继续运行)
05.11. 待 prompt 下方出现进度条就表示正在生成图片了,以下图为例,46% 是当前完成进度,23/50 是指总步数 50 步目前已完成 23 步,00:20<00:25 是指已用时 20 秒,预计还需 25 秒,1.07it/s 是指每秒生成 1.07 步,4046755246 是种子值。
05.12. 任务完成后会在此处显示,若一次生成了多张图片会依次在此显示,全部完成后会显示最后一张图片。
05.13. 你可以直接在这里右击保存图片,也可以在Google Drive 相应的文件夹内查看和下载图片,文件夹在 AI - StableDiffusion 这个目录下。
进阶教程______________________________________________________________________
05.14. 点击左侧的第四个「文件」图标展开文件窗口。
05.15. 点击文件窗口上方第一个「上传到会话存储空间」图标,选择你要上传的图片并点击「打开」,图片就会开始上传(你也可以把图片直接拖进文件窗口的空白处)。
05.16. 上传完成后图片会显示在文件窗口的列表中,找到你要使用的图片并点击文件名后方的三个小圆点,选择「复制路径」。
05.17. 将路径粘贴在如图位置,设置 init_strength 等参数,点击「代码执行程序」选择「全部运行」,如果之前已经运行过程序,直接点击 Image creation 单元前面的圆形按钮即可。
06. Deforum Stable Diffusion v0.3,这是由 deforum制作的 Google Colab 版本,无生成次数限制,需要注册 Hugging Face 账号,需要谷歌账号,需要科学上网,这个版本支持制作动画视频,如果运行过其他 Google Colab 版本的 Stable Diffusion 可以直接运行这个版本,如果未运行过其他版本的 Stable Diffusion 需要按「05.01. -05.06.」步骤进行操作,下载并上传「sd-v1-4.ckpt」文件至你的谷歌云盘,然后可以直接运行。这个版本我就不讲解了,如果有想做视频的朋友可以去研究一下。
07.Stable Diffusion Interpolation V2.1,这是由 @ygantigravity 和 @pharmapsychotic 制作的 Google Colab 版本,无生成次数限制,需要注册 Hugging Face 账号,需要谷歌账号,需要科学上网,这个版本有多文本多种子混合模式,似乎可以生成视频,感兴趣的朋友可以研究一下,同样需要下载并上传「sd-v1-4.ckpt」文件至谷歌云盘,然后再使用,若运行过其他 Google Colab 版本的 Stable Diffusion 可以直接运行。
08. 四行PaddleNLP代码体验Stable Diffusion,这是由凉心半浅良心人发布在飞桨平台的版本,有点类似于国内版的 Google Colab,也可以免费使用(有时长限制),这个我自己没有测试,看起来获取免费时长还是有点麻烦,供大家参考吧。
因为 Stable Diffusion 是一个开源模型,所以向公众开放以后涌现出了很多的开发者对其进行修改和加工,创造出了很多不同的版本,他们各有特色,大家可以选择适合自己的版本进行使用,也可以都试一试,选一个自己最顺手的版本。
本地运行______________________________________________________________________
以上是在线使用的教程,其实你也可以把 Stable Diffusion 部署到本地运行,但你需要一个至少有 10G 显存的 NVIDIA 显卡,已知官方 DreamStudio Beta 出一张 1024x512 的图需要大概 15秒,Google Colab 免费用户使用 TESLA T4 GPU 16G 显存出一张 1024x512 的图需要大概 42 秒,不过重点不是时间快慢,而是如果显存不够可能根本跑不起来,或者只能跑很小尺寸的图,所以大家依自己的情况而定,如果条件允许,也可以考虑部署到本地,但是会相对麻烦许多。这边也分享两个本地部署的教程给大家。
Stable Diffusion AI 绘画 |2022.08.27|本地部署 新手教程 by @stillcreek
【傻瓜教程】10分钟本地部署最新AI生成绘画(Stable Diffusion),有GPU就能玩! by @诡道荒行
更新一个本地版本,NMKD Stable Diffusion GUI - AI Image Generator,这个版本是打包好的程序,没有繁琐的部署过程,下载以后安装即可使用,目前仅支持 Nvidia 6G 以上的显卡,4G 可能参数设置的低一些也勉强能用,后续版本可能会增强对低显存的支持,仅支持 Windows 系统,这个版本的作者是N00MKRAD,使用此版的朋友可以加入他们的 Discord,如果使用遇到问题可以去上面反馈。
注意事项______________________________________________________________________
教程中所有准备工作部分仅第一次使用需要操作,之后可以直接运行,Google Colab 平台的版本可能会由于网络不稳定而报错,如果参考教程设置参数后仍有报错情况,请先仔细查阅错误提示,如果看不懂建议直接点击「代码执行程序」选择「全部运行」,重新运行即可。Stable Diffusion WebUI 1.4 版本 WebUI 页若操作没反应,尝试刷新页面后再操作即可,如果还有问题,建议重新运行。宽和高必须设置为 64 的整数倍,也就是 64、128、192、256、320、384、448、512、576、640、704、768、832、896、960、1024、1088、1152、1216、1280 等等,建议 1024x512 左右,大了会爆显存,会崩,可以小一点,RealESRGAN 的放大效果很好,可以出小图再用 RealESRGAN 放大,可放大 4 倍,且保持画质清晰。
如果你是首次接触 Google Colab,提醒一下,免费账号每天有使用时长限制,超过限额会有弹窗提醒,超额后从当日首次连接服务器开始计算 24 小时后恢复使用,如果想继续使用可以付费升级账号或者更换谷歌账号登录使用。
教程中所有准备工作都是为了下载模型,首次使用正常运行后模型就自动下载到你的云盘了,以后可以直接从云盘副本运行程序,不需要再按准备工作部分操作。
Stable Diffusion 的操作比较简单,效率也比较高,赶快去试一试吧!感谢 CompVis、Stability AI 和 LAION,感谢开发者们。
转载请注明:人工智能文本转图像模型 Stable Diffusion 入门教程 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号