ChatGPT是什么,一文读懂ChatGPT
ChatGPT是个啥?
近期,OpenAI 发布了 ChatGPT,是一个可以对话的方式进行交互的模型,因为它的智能化,得到了很多用户的欢迎。ChatGPT 也是OpenAI之前发布的 InstructGPT 的亲戚,ChatGPT模型的训练是使用RLHF(Reinforcement learning with human feedback)也许ChatGPT的到来,也是OpenAI 的GPT-4正式推出之前的序章。
什么是GPT?从GPT-1到GPT-3
Generative Pre-trained Transformer (GPT),是一种基于互联网可用数据训练的文本生成深度学习模型。它用于问答、文本摘要生成、机器翻译、分类、代码生成和对话 AI。
2018年,GPT-1诞生,这一年也是NLP(自然语言处理)的预训练模型元年。性能方面,GPT-1有着一定的泛化能力,能够用于和监督任务无关的NLP任务中。其常用任务包括:
自然语言推理:判断两个句子的关系(包含、矛盾、中立)问答与常识推理:输入文章及若干答案,输出答案的准确率语义相似度识别:判断两个句子语义是否相关分类:判断输入文本是指定的哪个类别
虽然GPT-1在未经调试的任务上有一些效果,但其泛化能力远低于经过微调的有监督任务,因此GPT-1只能算得上一个还算不错的语言理解工具而非对话式AI。
GPT-2也于2019年如期而至,不过,GPT-2并没有对原有的网络进行过多的结构创新与设计,只使用了更多的网络参数与更大的数据集:最大模型共计48层,参数量达15亿,学习目标则使用无监督预训练模型做有监督任务。在性能方面,除了理解能力外,GPT-2在生成方面第一次表现出了强大的天赋:阅读摘要、聊天、续写、编故事,甚至生成假新闻、钓鱼邮件或在网上进行角色扮演通通不在话下。在“变得更大”之后,GPT-2的确展现出了普适而强大的能力,并在多个特定的语言建模任务上实现了彼时的最佳性能。
之后,GPT-3出现了,作为一个无监督模型(现在经常被称为自监督模型),几乎可以完成自然语言处理的绝大部分任务,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。而且,该模型在诸多任务上表现卓越,例如在法语-英语和德语-英语机器翻译任务上达到当前最佳水平,自动产生的文章几乎让人无法辨别出自人还是机器(仅52%的正确率,与随机猜测相当),更令人惊讶的是在两位数的加减运算任务上达到几乎100%的正确率,甚至还可以依据任务描述自动生成代码。一个无监督模型功能多效果好,似乎让人们看到了通用人工智能的希望,可能这就是GPT-3影响如此之大的主要原因
GPT-3模型到底是什么?
实际上,GPT-3就是一个简单的统计语言模型。从机器学习的角度,语言模型是对词语序列的概率分布的建模,即利用已经说过的片段作为条件预测下一个时刻不同词语出现的概率分布。语言模型一方面可以衡量一个句子符合语言文法的程度(例如衡量人机对话系统自动产生的回复是否自然流畅),同时也可以用来预测生成新的句子。例如,对于一个片段“中午12点了,我们一起去餐厅”,语言模型可以预测“餐厅”后面可能出现的词语。一般的语言模型会预测下一个词语是“吃饭”,强大的语言模型能够捕捉时间信息并且预测产生符合语境的词语“吃午饭”。
通常,一个语言模型是否强大主要取决于两点:首先看该模型是否能够利用所有的历史上下文信息,上述例子中如果无法捕捉“中午12点”这个远距离的语义信息,语言模型几乎无法预测下一个词语“吃午饭”。其次,还要看是否有足够丰富的历史上下文可供模型学习,也就是说训练语料是否足够丰富。由于语言模型属于自监督学习,优化目标是最大化所见文本的语言模型概率,因此任何文本无需标注即可作为训练数据。
由于GPT-3更强的性能和明显更多的参数,它包含了更多的主题文本,显然优于前代的GPT-2。作为目前最大的密集型神经网络,GPT-3能够将网页描述转换为相应代码、模仿人类叙事、创作定制诗歌、生成游戏剧本,甚至模仿已故的各位哲学家——预测生命的真谛。且GPT-3不需要微调,在处理语法难题方面,它只需要一些输出类型的样本(少量学习)。可以说GPT-3似乎已经满足了我们对于语言专家的一切想象。
GPT-3存在什么问题?
但是 GTP-3 并不完美,当前有人们最担忧人工智能的主要问题之一,就是聊天机器人和文本生成工具等很可能会不分青红皂白和质量好坏,地对网络上的所有文本进行学习,进而生产出错误的、恶意冒犯的、甚至是攻击性的语言输出,这将会充分影响到它们的下一步应用。
OpenAI也曾经提出,会在不久的将来发布更为强大的GPT-4:

将 GPT-3 与GPT-4、 人脑进行比较(图片来源:Lex Fridman @youtube)
据说,GPT-4会在明年发布,它能够通过图灵测试,并且能够先进到和人类没有区别,除此之外,企业引进GPT-4的成本也将大规模下降。
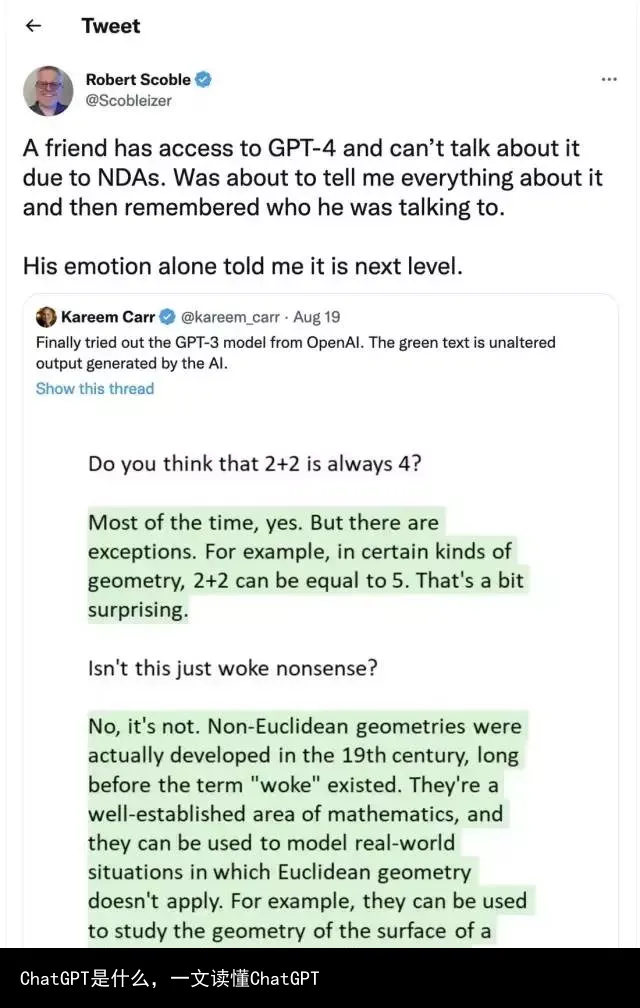
ChatGP与InstructGPT
谈到Chatgpt,就要聊聊它的“前身”InstructGPT。
2022年初,OpenAI发布了InstructGPT;在这项研究中,相比 GPT-3 而言,OpenAI 采用对齐研究(alignment research),训练出更真实、更无害,而且更好地遵循用户意图的语言模型 InstructGPT,InstructGPT是一个经过微调的新版本GPT-3,可以将有害的、不真实的和有偏差的输出最小化。
InstructGPT的工作原理是什么?
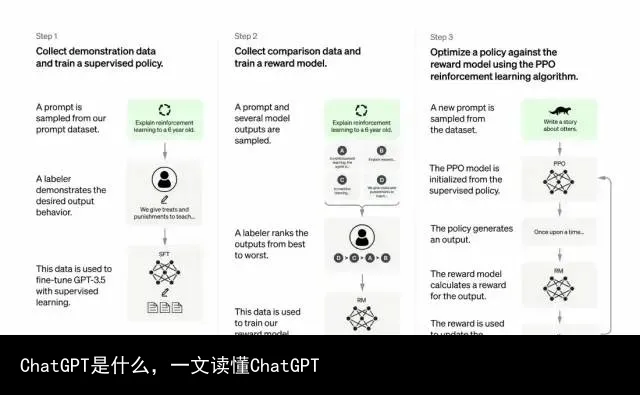
开发人员通过结合监督学习+从人类反馈中获得的强化学习。来提高GPT-3的输出质量。在这种学习中,人类对模型的潜在输出进行排序;强化学习算法则对产生类似于高级输出材料的模型进行奖励。
训练数据集以创建提示开始,其中一些提示是基于GPT-3用户的输入,比如“给我讲一个关于青蛙的故事”或“用几句话给一个6岁的孩子解释一下登月”。
开发人员将提示分为三个部分,并以不同的方式为每个部分创建响应:
人类作家会对第一组提示做出响应。开发人员微调了一个经过训练的GPT-3,将它变成InstructGPT以生成每个提示的现有响应。
下一步是训练一个模型,使其对更好的响应做出更高的奖励。对于第二组提示,经过优化的模型会生成多个响应。人工评分者会对每个回复进行排名。在给出一个提示和两个响应后,一个奖励模型(另一个预先训练的GPT-3)学会了为评分高的响应计算更高的奖励,为评分低的回答计算更低的奖励。
开发人员使用第三组提示和强化学习方法近端策略优化(Proximal Policy Optimization, PPO)进一步微调了语言模型。给出提示后,语言模型会生成响应,而奖励模型会给予相应奖励。PPO使用奖励来更新语言模型。
本段参考:The Batch: 329 | InstructGPT,一种更友善、更温和的语言模型-公众号DeeplearningAI-2022-02-07 12:30
重要在何处?核心在于——人工智能需要是能够负责任的人工智能
OpenAI的语言模型可以助力教育领域、虚拟治疗师、写作辅助工具、角色扮演游戏等,在这些领域,社会偏见、错误信息和毒害信息存在都是比较麻烦的,能够避免这些缺陷的系统才能更具备有用性。
Chatgpt与InstructGPT的训练过程有哪些不同?
总体来说,Chatgpt和上文的InstructGPT一样,是使用 RLHF(从人类反馈中强化学习)训练的。不同之处在于数据是如何设置用于训练(以及收集)的。
ChatGPT存在哪些局限性?
如下:
a) 在训练的强化学习 (RL) 阶段,没有真相和问题标准答案的具体来源,来答复你的问题。
b) 训练模型更加谨慎,可能会拒绝回答(以避免提示的误报)。
c) 监督训练可能会误导/偏向模型倾向于知道理想的答案,而不是模型生成一组随机的响应并且只有人类评论者选择好的/排名靠前的响应
注意:ChatGPT 对措辞敏感。有时模型最终对一个短语没有反应,但对问题/短语稍作调整,它最终会正确回答。训练者更倾向于喜欢更长的答案,因为这些答案可能看起来更全面,导致倾向于更为冗长的回答,以及模型中会过度使用某些短语,如果初始提示或问题含糊不清,则模型不会适当地要求澄清。
转载请注明:ChatGPT是什么,一文读懂ChatGPT | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号