北大用ChatGPT组建了个开发团队:大模型分饰多角色,协同完成软件开发任务
人类可以通过合作的方式解决复杂问题,这种模式同样适用于 AI 领域。
「一个人的能力有限,一支团队的力量无限」,这一句话在现实世界的软件开发中体现的淋漓尽致。对于复杂的任务,人们通过团队合作策略来解决。但在 AI 世界中,这样的模式是否也适用呢?
今年4月,北京大学李戈教授团队提出了一种全新的 self-collaboration(自合作)模式。它允许多个大模型扮演不同的角色,组成了一个无需人类参与的软件开发团队,通过大模型间的合作和交互,自主完成整个软件开发流程,甚至包括一些复杂的代码生成任务。

尽管大型语言模型 (简称为:大模型) 在代码生成方面已经展示出了惊人的能力,但是在处理复杂任务上仍然存在挑战。在现实中的软件开发过程中,人们通常通过协同团队工作的策略来解决复杂的任务,这种策略能够显著地控制开发的复杂性并提高软件的质量。
受此启发,研究者提出了一个使用大模型进行代码生成的 self-collaboration 框架。具体来说,通过角色指令,1) 多个大型语言模型扮演不同的 "专家" 角色,每个模型负责处理复杂任务中的特定子任务;2) 规定合作和交互的方式,使不同的角色形成一个虚拟团队,帮助彼此完成工作,最终无需人为干预就能共同完成代码生成任务。
为了有效地组织和管理这个虚拟团队,研究者巧妙地将软件开发方法论中的瀑布模型融入到了框架中,组建了一个由三个 ChatGPT 角色(即分析师、程序员和测试员)组成的基础团队,实施软件开发过程中的分析、编码和测试阶段。
实验结果表明,与直接利用大模型代码生成相比,self-collaboration 代码生成的性能大幅提升,甚至让 GPT-3.5 超越了 GPT-4。此外,研究者还展示了 self-collaboration 能使大模型有效地处理更复杂的实际代码项目,而这些项目往往是直接代码生成难以解决的。
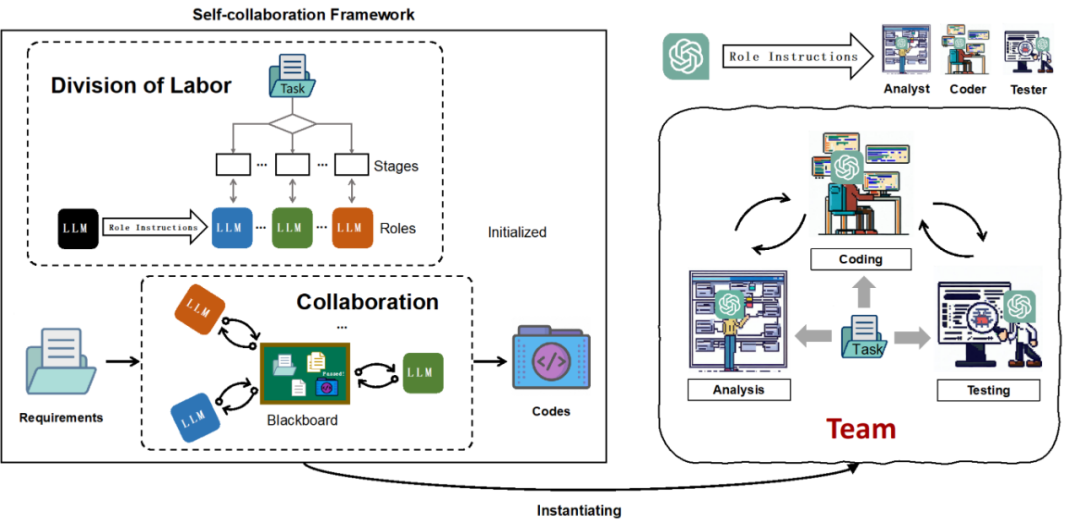
下面具体介绍一下 Self-collaboration 框架以及在该框架基础上按照软件开发方法论组建虚拟团队的实例。
Self-collaboration 框架
给定需求 x,利用大模型执行 Self-collaboration 以生成输出 y。该任务定义为T:x→y。Self-collaboration 框架由两部分组成:分工和合作。

众所周知,大模型对上下文非常敏感,因为它们在训练时,被要求根据前面的文字预测后续文字。因此,一种广泛使用的方式是通过指令或提示来控制大模型的生成。研究者采用特定类型的指令为大模型分配身份和职责,被称为角色指令。具体来说,研究者要求大模型扮演与其职责紧密相关的特定角色并且传达这个角色应该执行的详细任务。
使用角色指令的优势在于它们仅需要在交互开始时被提供一次。在随后的交互中,传达的只是意图,而不是指令和意图的组合。因此,角色指令提升了后续沟通合作的整体效率和清晰度。
在合作部分,研究者关注于促进在 self-collaboration 框架内承担不同角色的大模型之间的有效交互。每个大模型在其指定角色指令的指导下,通过履行其分配的职责为整体任务做出贡献。随着阶段的进展,大模型与其他大模型交流他们的输出,交互信息并输出 y 。
利用角色指令,可以有效控制大模型的输出格式。结合语言模型的基础方面,这可以初步建立大模型之间的通信。
合作部分可以形式化为:
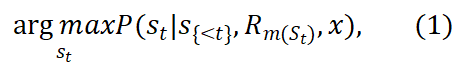



实例化
研究者将软件工程方法论中的经典瀑布模型引入到自协作框架中,使代码生成的团队协作更加高效。具体来说,研究者设计了一个由分析、编码和测试三个阶段组成的简化瀑布模型,作为自协作代码生成的实例。该实例的工作流程遵循瀑布模型从一个阶段流向下一阶段,如果发现问题,则返回上一阶段进行细化。因此,研究者建立了一个基本团队,包括分析师、编码员和测试员,负责分析、编码和测试阶段,如图 1(右)所示。这三个不同的角色被分配以下任务:
分析师:分析师的目标是制定高层次的 plan 并专注于指导程序员编写程序,而不是深入研究实现细节。给定需求 x,分析师将 x 分解为几个易于解决的子任务,以方便程序员直接实施,并制定概述实施主要步骤的 plan。
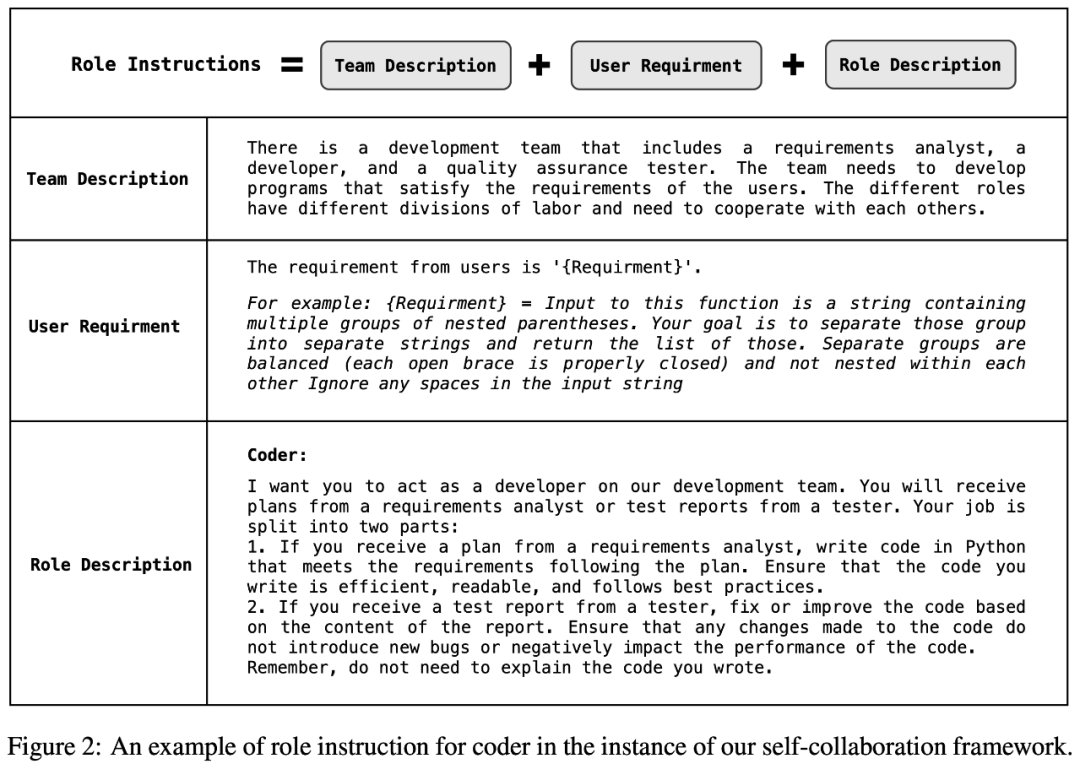
程序员:作为该团队的核心角色,程序员将在整个开发过程中接收来自分析师的 plan 或来自测试人员的测试报告。因此,研究者通过角色说明将两项主要职责分配给程序员:1. 编写满足指定要求的代码,遵守分析师提供的 plan。2. 修复或细化代码,考虑到测试人员反馈的测试报告反馈。编码器角色指令的详细信息如图 2 所示。
测试员:测试员获取程序员编写的代码,然后记录包含各个方面(例如功能性、可读性和可维护性)的测试报告。研究者提倡模型模拟测试过程并生成测试报告,而不是生成测试用例然后通过执行手动测试代码,从而促进交互并避免额外的工作。

实验结果
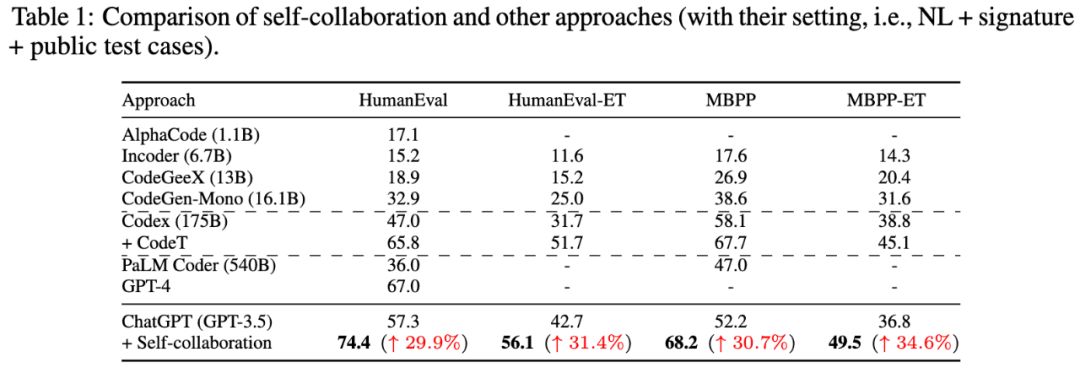
研究者将 self-collaboration 代码生成与各种最先进(SOTA)方法进行比较,实验结果表明,self-collaboration 框架显著提高了基础大模型的性能。值得注意的是,即使是一个简单的三人团队(包括分析师、程序员和测试员),基于 ChatGPT (GPT-3.5) 的 self-collaboration 代码生成在四个代码生成基准测试中也取得了最佳性能,甚至超过了 GPT-4。考虑到基础大模型本身的差距,将 self-collaboration 框架应用于更强大的模型,例如 GPT-4,将产生更好的结果。
 研究者进一步研究了仅使用自然语言描述的代码生成,这种设置更贴近实际的软件开发。在此设置下,研究者比较了由 self-collaboration 框架实例化的初等团队中每个 ChatGPT 角色的表现,如表 2 所示。实验结果表明,与仅使用程序员角色相比,无论是二位角色还是三位角色组建的团队,性能都有显著提高。
研究者进一步研究了仅使用自然语言描述的代码生成,这种设置更贴近实际的软件开发。在此设置下,研究者比较了由 self-collaboration 框架实例化的初等团队中每个 ChatGPT 角色的表现,如表 2 所示。实验结果表明,与仅使用程序员角色相比,无论是二位角色还是三位角色组建的团队,性能都有显著提高。 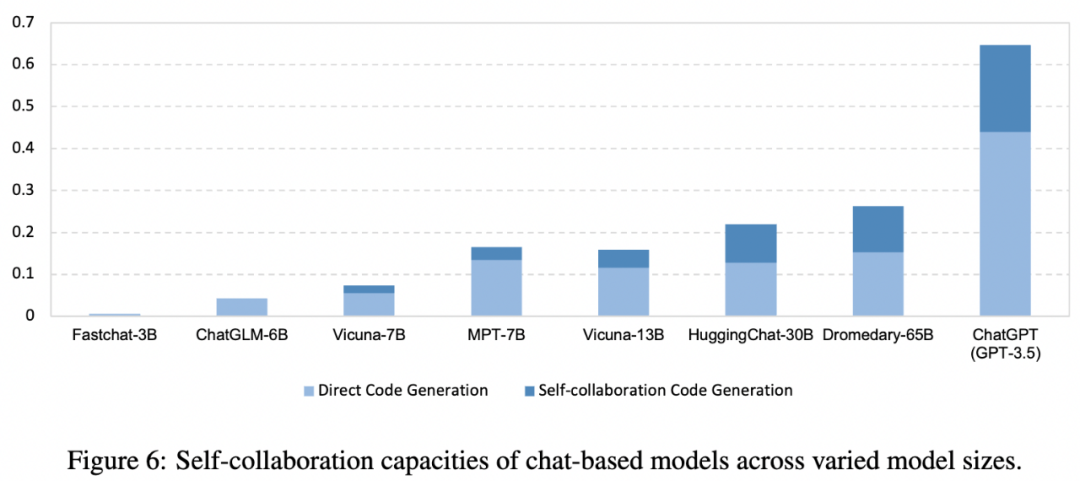 研究者还研究了在不同模型大小下大模型的自合作能力。研究者评估了 self-collaboration 方法在处理复杂任务时的有效性,特别是那些对直接代码生成具有挑战性的任务。对于此类任务,研究者采用 self-collaboration 策略作为解决方案。如图 6 所示,随着模型规模的扩大,大模型的 coding 能力通常呈现出增加的趋势,而自合作能力在 7B 参数量左右开始显现出来,随后不断提升。实验结果表明自合作有助于激发大模型的潜在智能。
研究者还研究了在不同模型大小下大模型的自合作能力。研究者评估了 self-collaboration 方法在处理复杂任务时的有效性,特别是那些对直接代码生成具有挑战性的任务。对于此类任务,研究者采用 self-collaboration 策略作为解决方案。如图 6 所示,随着模型规模的扩大,大模型的 coding 能力通常呈现出增加的趋势,而自合作能力在 7B 参数量左右开始显现出来,随后不断提升。实验结果表明自合作有助于激发大模型的潜在智能。 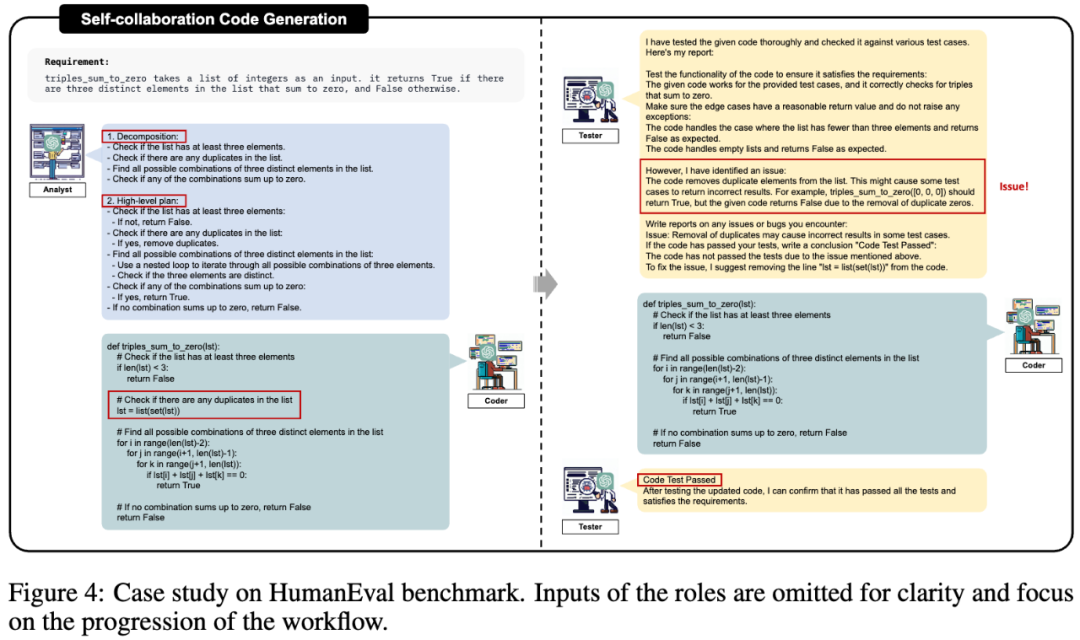 此外,研究者展示了一个 self-collaboration 代码生成示例,如图 4 所示。在这份测试报告中,测试员指出所实现的代码可能会导致从列表中删除重复元素,从而可能导致某些边缘测试用例失败。因此,建议从实现的代码中删除行 “lst = list (set (lst))”。程序员随后根据测试报告中的反馈删除了 “lst = list (set (lst))” 行。在最后一次交互中,测试员确认修改后的代码已经通过所有测试,满足要求,至此代码生成过程结束。
此外,研究者展示了一个 self-collaboration 代码生成示例,如图 4 所示。在这份测试报告中,测试员指出所实现的代码可能会导致从列表中删除重复元素,从而可能导致某些边缘测试用例失败。因此,建议从实现的代码中删除行 “lst = list (set (lst))”。程序员随后根据测试报告中的反馈删除了 “lst = list (set (lst))” 行。在最后一次交互中,测试员确认修改后的代码已经通过所有测试,满足要求,至此代码生成过程结束。 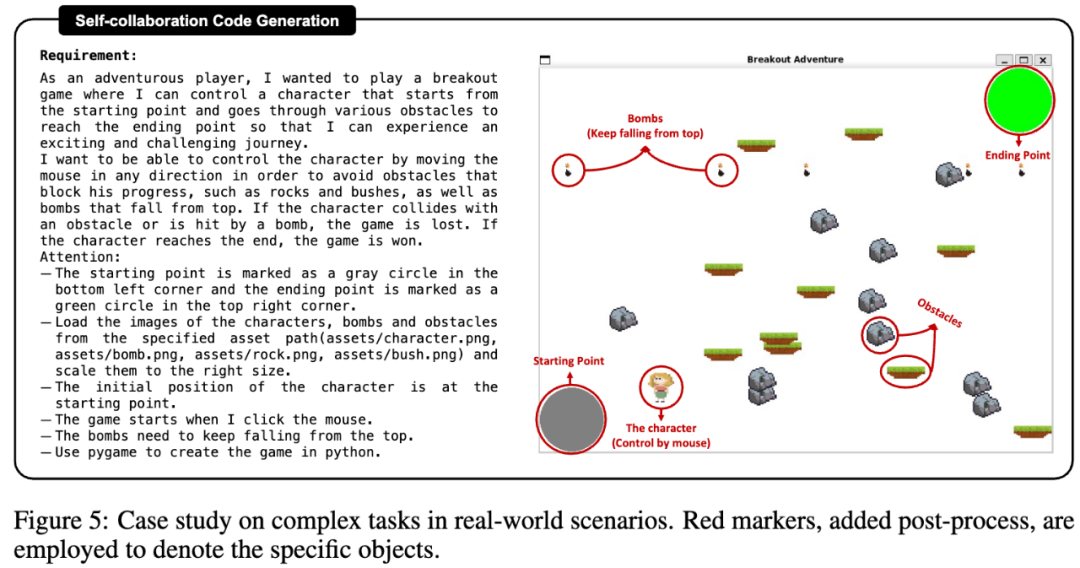

研究者还将 self-collaboration 框架应用于更复杂的实际代码项目的两个例子,分别是游戏开发和网页制作,如图 5 和图 9 所示。self-collaboration 可以生产完整的游戏逻辑和令人满意的游戏界面,对于天气预报网页的开发,也可以正确调用外部天气接口,实现所有功能。而直接代码生成则并没有覆盖所有要求的功能并且存在 bug,效果不佳。
总之,self-collaboration 框架在代码生成任务中表现出显著的性能提升,与单一角色相比,多角色团队能够更有效地处理各种问题和挑战。这种方法为自然语言处理和代码生成领域提供了新的研究方向,值得进一步探讨和优化。未来的工作可能包括对更多角色和更强大模型的探索,以及将 self-collaboration 框架应用于其他自然语言处理任务。
结论
在该工作中,研究者提出了一种 self-collaboration 框架,其目的是通过合作和交互方法来增强大模型的问题解决能力。具体而言,研究者探索了 ChatGPT 在促进基于团队的代码生成和合作方面的软件开发过程中的潜力。为此,研究者组建了一个由三个不同的 ChatGPT 角色组成的初等团队,目的是全面解决代码生成任务。为了评估 self-collaboration 框架的有效性和泛化性能,研究者针对各种代码生成基准进行了广泛实验。实验结果提供了大量证据支持 self-collaboration 框架的有效性和普适性。研究者认为,让模型能够组建自己的团队并合作完成复杂的任务是实现 AGI 的关键一步。
原文链接:https://mp.weixin.qq.com/s/MqB2Uc2nZ0w8hESi_PRrUg
转载请注明:北大用ChatGPT组建了个开发团队:大模型分饰多角色,协同完成软件开发任务 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号