一、Stable diffusion是什么
Stable diffusion 是 Stability AI 训练出来的一个图像模型。它可以通过文字生成图像,也可以通过图像生成其他图像。
Stable diffusion在训练时大概用了60亿张图像,再加上强大的硬件设备(256张A100显卡)来进行训练,成本大约两千万人民币。训练完后 Stability AI 就把它开源出来了,让所有人都可以免费下载使用,我们现在使用的模型都是基于Stable diffusion 训练的模型微调出来的。所以网上那么多AI生成的人物图像,基本上都可以看出有一点相似之处,特别是脸型。
二、使用 Stable diffusion 的三大要素
1、Python

现在几乎所有的AI,都建立在同一个程序上面,这个程序就是 Python,所以我们在本地部署 Stable diffusion 的时候前置条件就有一个是安装 Python。
但也并不是 Python 的版本越新就越好,因为 Python 有很多针对神经网络的组件都已经打包好了,而这些组件都有对应的版本上限,比如 Pytorch 1.13 对应的 Python 版本上限就是3.10.x。所以部署 Stable diffusion 的 Python 版本要求是 3.10.6 就是这么来的,如果安装了更新的版本,可能就会带来更多的错误。
2、CUDA(Compute Unified Device Architecture)

同样的,现在几乎所有的AI神经网络,用的都是同一个运算平台,也就是 CUDA。而 CUDA 又是 NVIDIA独有的一套架构,所以才说为什么部署 Stable diffusion 显卡要求是N卡,这也是非常重要的,一张好的显卡可以让你的出图速度快上几倍甚至几十倍。
3、Git
因为 Stable diffusion 是一个开源软件,而几乎所有的开源软件都在微软的子公司github 上面,所以想要使用这些开源软件,就必须安装 Git,这没什么可说的。
这就是我们使用 Stable diffusion 的三大要素,两个软件一个硬件,可以说缺一不可。
三、Webui 是什么
Stable diffusion 一开始的时候是基于命令的形式来使用的,所有参数以及模型都需要通过命令来进行设定,比如 正反向提示词、宽高、采样步数等。
但是所有参数都通过命令的形式来输入就很不方便,于是automatic1111 大神就做了一个可视化的 webui 网页插件,并把所有的扩展功能都整合到一起,就有了我们现在使用的 webui。
我们使用的 Stable diffusion,除了文生图跟图生图两个功能是源自于 Stable diffusion 本身之外,别的功能其实都是第三方制作的扩展插件,比如提示词反推、图片放大等,这些扩展功能都是 automatic1111 大神整合进去的,当然也不一定都是 automatic1111 做的,也有些是其他人整合后交给 automatic1111 进行合并的。
因为有强大社群的支持,所以 Stable diffusion 也变得非常多样非常强大,我们平时更新的东西,其实都是更新webui的版本或者是扩展插件的版本,跟使用的 Stable diffusion 版本没有关联,你想要使用 Stable diffusion 的哪一个版本,全看你使用的是哪个模型。
但又因为开源,没有门槛,所以功能会很杂,也会有许多bug,所以我们在使用过程中遇到各种问题不要觉得奇怪,这是很正常的事,只要注意做好备份就行。
四、优缺点
1、优点
因为开源,所以对所有人免费,而且还有各路大神开发了各种扩展插件,附加的功能非常多。现下最流行的就是lora 跟 Controlnet 了,lora 可以改变画风以及训练各种人物和角色,Controlnet则可以控制角做出相应的动作,这些功能都是目前其他AI比较难以做到的。
2、缺点
也因为是开源的,功能非常杂乱,如果对程序基础没有一定的了解,只是按照网络上的教学一直下载安装扩展插件,最后的下场就是 webui 会崩坏到需要重新安装,然后安装又会遇到各种问题。
在目前 Stable diffusion 还不是很成熟的情况下,要想使用好它还是有一定难度,相比于其他的画图AI,比如 midjourney 只需要聊聊天就能直接画图,真的要难很多。
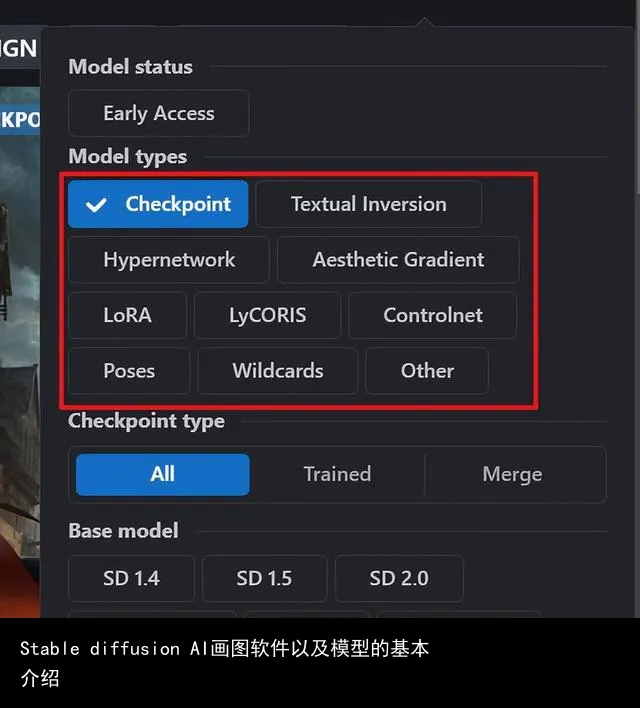
五、模型简介
在介绍模型之前先说一下模型文件的格式。刚开始的时候,模型文件是有非常多格式的。比如:.onnx、.pt、.ckpt、.bin、.pth 等等,但因为这类格式的模型文件会有被植入木马的风险,所以Hugging face 开发了一个全新的文件格式,扩展名为 .safetensors,这类文件格式可以保证下载的模型不会带有木马,大大提高了安全性。
但是也会给新手带来一定的使用难度,因为现在大部分的模型都是safetensors 格式,下载下来之后根本不清楚要放哪里,或者多种模型同时下载,下载之后也会分不清哪个文件是什么模型,下面就以C站的分类为例对我们经常使用的模型作一些简单的介绍。
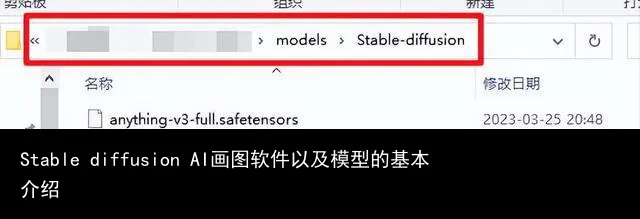
1、Checkpoint模型
Checkpoint 模型也就是 Stable diffusion 模型,文件格式为. ckpt 或者 .safetensors,该模型文件最小也接近2G,最大我见过的是7.7G,所以看到这样的文件大小,基本上就可以确定是 Checkpoint模型。该模型放在这个文件夹下:主程序目录/models/stable-diffuison 。
2、Textual Inversion
也就是 embedding模型,它是用来用来调整模型的文本编码器微调模型,扩展名是 .pt 或者 .safetensors ,因为它只改变文字向量,所以模型都非常小,通常都在30KB以内。该模型放在这个文件夹下面:主程序目录/embeddings 。

3、Hypernetworks模型
该模型是用来微调 Stable diffusion 模型神经网络的微调模型,通常用来对图片的风格进行微调,扩展名是 .pt,文件大小从20MB到300MB都有。该模型放在这个文件夹下:主程序目/models/hypernetworks 。
4、lora模型与lycoris模型
lora 是目前最流行的微调模型,它可以微调 Stable diffusion 模型的神经网络,lora 与 lycoris 的区别只在于 lycoris 的微调范围更大,所以 lycoris 的文件也会比较大。这两个模型的扩展名都是.safetensors,大小也是不固定的,从4MB到300MB的都有,在使用上只有一个差异,要使用 lycoris 需要安装额外的扩展插件才可以。这两个模型都是放在这个文件夹下:主程序目录/models/lora 。

5、vae模型
vae 模型主要用来提高画面的亮度和饱和度,同时也会对画面进行校正和补光,可以理解为PS里的滤镜。其实每个 Stable diffusion 模型都含有一个 vae,但因为原始模型通常做得不够好,所以一般都建议再下载一个 anything 的 vae 模型或者 Stable diffusion 官方微调过的 vae (vae-ft-mse-840000-ema-pruned) ,vae 模型的文件扩展名是.pt 或 .safetensors ,下载后放在这个文件夹下:主程序目录/models/vae 。
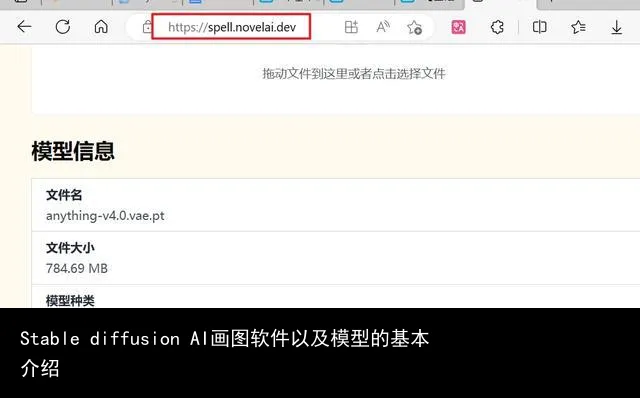
以上就是关于模型的基本介绍,有没有发现看完了还是不知道各种模型要怎么区分。
所以这里再分享一个模型解析的网站,只要把你下载的模型放上去,就能显示这个是什么模型并且应该放在哪里使用。该网站也是秋叶大佬提供的,有需要的话,链接在图片里自取。
六、模型的使用
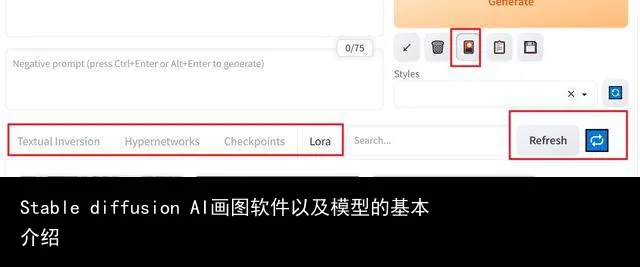
模型的使用很简单,对于 Checkpoint 模型以及 vae 模型,下载完成放进对应的文件夹后,只需要点击一下 webui 界面对应的蓝色刷新按钮,然后从下拉列表中选择就可以。
如果是其他模型,则需要点击 Generate生成按钮下方的小红书按钮,在打开的列表里面选择对应的模型进行使用,同样的,如果没有出现下载的模型,点击一下右侧蓝色的刷新按钮即可。
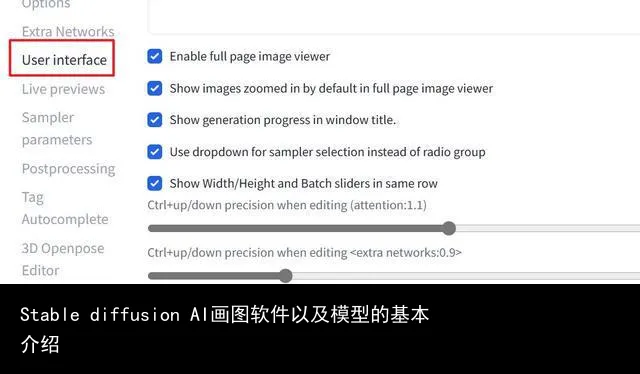
这里主要说一下 vae 模型的选择框怎么调出来。如果你用的是一键安装包,那安装完成后就会直接有 vae 的选择框,如果是用标准安装的,那安装完成后应该是像下面这样的,只有 Checkpoint 模型选择框。

这时需要进入 Settings 设置选项卡,左侧栏选择 User interface用户界面,在右侧找到 Quicksettings list快速设置列表,在 “sd_model_checkpoint” 后面加上 ”,sd_vae“ ,然后保存设置并重启界面就可以了,要注意用英文逗号隔开,设置完成后应该是这个样子的 ”sd_model_checkpoint,sd_vae” 。
以上就是关于 Stable diffusion 以及模型的基本介绍,如果有不清楚或者需要补充的地方,欢迎评论区留言讨论。
转载请注明:Stable diffusion AI画图软件以及模型的基本介绍 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号