想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符
我们知道在使用 GPT 和 LLaMA 等大型语言模型时,输入的 prompt 存在字符数限制,比如 ChatGPT 目前的输入字符限制是 4096 个字符。这会限制上下文学习和思维链等技术的发挥空间,毕竟用户只能提供有限的示例数量。近日,Nous Research、EleutherAI 和日内瓦大学的一个研究团队提出了一种扩展上下文窗口的方案 YaRN ,并在实验中取得了优于其它所有方法的效果,而且他们还发布了使用 YaRN 微调过的 LLaMA 2 7B/13B 模型,其上下文窗口为 64k 和 128k。


-
动态 NTK 插值法,无需微调就能用于预训练模型。 -
部分 NTK 插值法,当使用少量更长上下文的数据微调后,模型能取得最佳表现。
方法
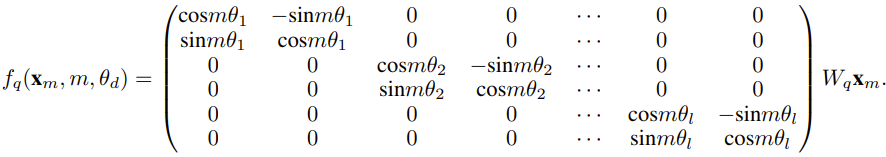 对于使用固定上下文长度预训练的 LLM,如果使用位置插值(PI)来扩展上下文长度,则可以表示为:
对于使用固定上下文长度预训练的 LLM,如果使用位置插值(PI)来扩展上下文长度,则可以表示为: 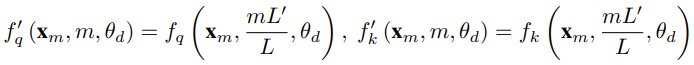
实验
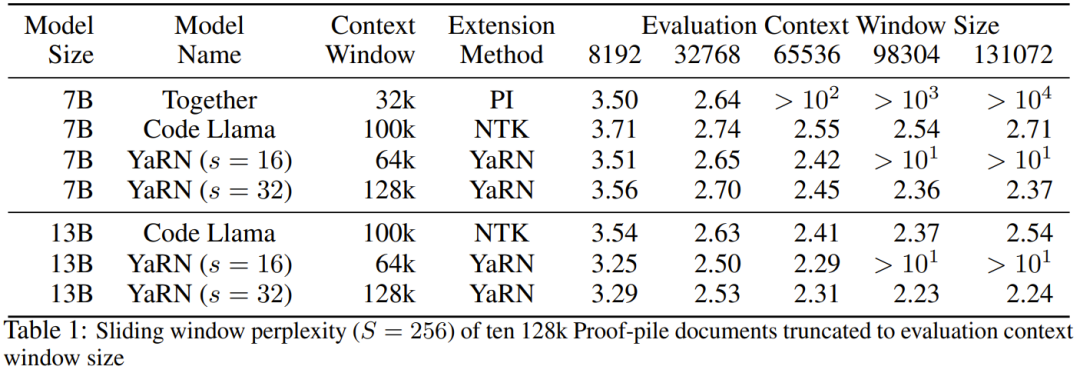 表 2 展示了在 50 个未截断的 GovReport 文档(长度至少为 16k token)上的最终困惑度。
表 2 展示了在 50 个未截断的 GovReport 文档(长度至少为 16k token)上的最终困惑度。 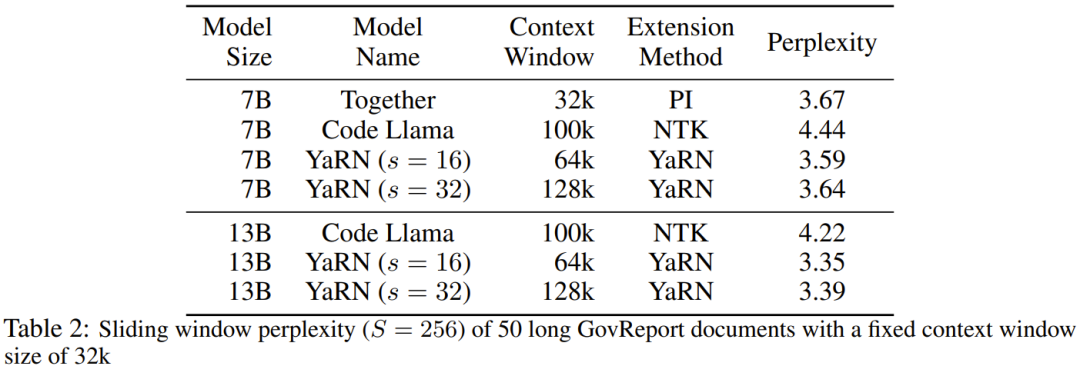 为了测试使用上下文扩展时模型性能的劣化情况,研究者使用 Hugging Face Open LLM Leaderboard 套件评估了模型,并将其与 LLaMA 2 基准模型以及公开可用的 PI 和 NTK 感知型模型的已有分数进行了比较。表 3 总结了实验结果。
为了测试使用上下文扩展时模型性能的劣化情况,研究者使用 Hugging Face Open LLM Leaderboard 套件评估了模型,并将其与 LLaMA 2 基准模型以及公开可用的 PI 和 NTK 感知型模型的已有分数进行了比较。表 3 总结了实验结果。 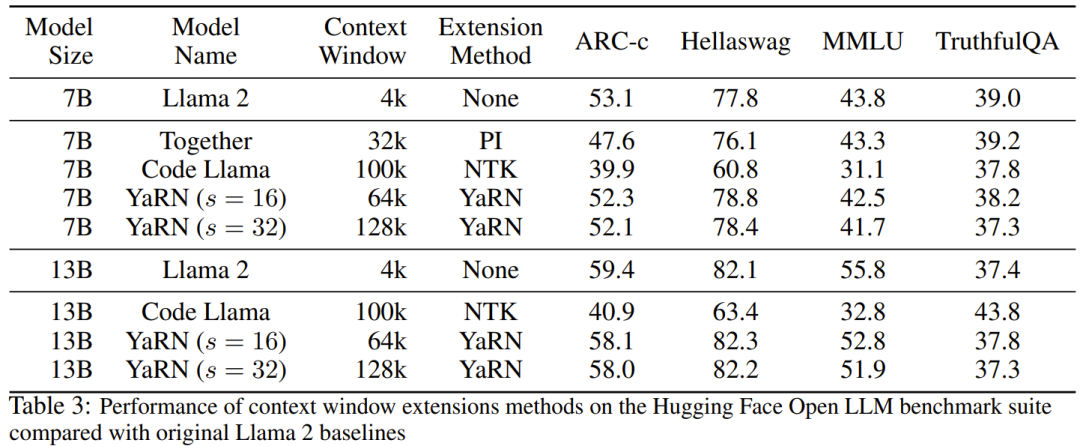
版权声明:MM 发表于 2023-09-13 10:32 AM。
转载请注明:想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
转载请注明:想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章
GO123.AI网址大全是猎户星空旗下的一款收集流行AI应用网址的平台,提供AI作图、聊天、视频编辑等资源。我们还提供ChatGPT的新手教程和高级玩法指导,为用户提供最全面、最实用的服务。欢迎来猎户星空旗下的GO123.AI网址大全,一起探索AI应用的无限可能!

 京公网安备 11010502044423号
京公网安备 11010502044423号