最近可以在各个平台上看到stable diffusion的相关案例,各种text2img或是img2img的应用都有非常惊艳的效果。
虽然类似功能的DALL-E已经发布很久了,甚至性能更为强大,但是stable diffusion模型开源所带来的影响力是DALL-E所远远不能比拟的,投石入河激起的涟漪层层荡开,许多新的服务、网站衍生而出,不禁让人吃惊:怎么会那么火?
相关资源
这里简单罗列下stable diffusion相关的各类资源,包括代码、模型等等。
官网:https://ommer-lab.com/research/latent-diffusion-models/论文:https://arxiv.org/abs/2112.10752Github地址:https://github.com/CompVis/stable-diffusion模型下载地址: https://huggingface.co/CompVis/stable-diffusion-v1-2https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main/safety_checker
huggingface权限申请
目前stable diffusion的模型都已经在huggingface上开源发布了,主页上也说明了具体的使用方法,但是由于这种生成式的模型容易被滥用,因此使用受限无法直接下载,还需要在huggingface上注册个人账号后申请使用。
注册账号后,在https://huggingface.co/settings/tokens可以得到对应的tokens,然后本地huggingface-cli login后输入,就可以愉快的使用stable diffusion的相关模型了。如果没有token,代码运行会报错:
另外Access repository后,就可以下载模型了。

依赖库安装
huggingface中所提供的示例代码,所依赖的是diffusers这个库,访问这个库的GitHub地址:https://github.com/huggingface/diffusers,官方的说法是pip安装就可以。
不过实际测试发现,pip默认安装的版本是0.1.2,而不是推荐的0.2.4,同时即使强制安装了0.2.4,img2img和in-painting所使用的类在这个包中也并不存在,因此更建议的安装方法是clone GitHub仓库到本地后,通过python3 setup.py install安装实现。
text2img测评
简单测评下text2img的功能:输入一段text文字,模型会基于这段描述性文字生成图像img。
代码使用官方提供的示例就可以,由于模型已经下载,因此将路径指定为模型地址即可:
from torch import autocast
from diffusers import StableDiffusionPipelinepipe = StableDiffusionPipeline.from_pretrained(/stable-diffusion-v1-4)
prompt = "a photo of a flying dog"
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("/test.png”)
其中pipe的结构如下:
>>> pipe
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.2.4",
"feature_extractor": [
"transformers",
"CLIPFeatureExtractor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
随意测试了一些prompt的生成效果如下:
a photo of a flying dog

a photo of an astronaut riding a horse on moon

a photo of a smiling Chinese women

a photo of a smiling American women

可以看到大部分图像的生成效果其实都还可以,不过这个Chinese women看的让人头秃,训练数据怕不是有眯眯眼的歧视问题。。。
在线资源
除了通过本地下载模型调试代码,stable diffusion还有很多开源的服务,便于做快速测试。 以https://huggingface.co/spaces/stabilityai/stable-diffusion 为例,同样可以输入一句prompt生成图像,不过由于资源紧张需要排队使用,排队时间也可能比较长。
这里同样测试了几个prompt,效果如下:
a photo of a smiling Chinese women

a robot reading the book and playing the piano

嗯,看起来训练数据的眯眯眼问题是没跑了。
此外,还有一个开源的prompt网站:https://lexica.art/,可以提供参考的prompt用于生成图像,支持DALL-E,stable diffusion等模型。
不过目前stable diffusion的相关服务还不完善,摘录部分DALL-E的prompt与图像示例如下:
ultra nekopara fantastically detailed reflecting eyes modern anime style art cute detailed ears cat girl neko dress portrait shinkai makoto vibrant Studio ghibli kyoto animation hideaki anno Sakimichan Stanley Artgerm Lau Rossdraws James Jean Marc Simonetti elegant highly detailed digital painting artstation pixiv cyberpunk

a hyperdetailed matte painting of a german romantic tree emerging from an oceanographic landscape, magic realism painting, trending on artstation

小结
人工智能喊得这些年,除了被吐槽人工智障外,自动驾驶看着还是有些远,下围棋也终究是少数人的爱好,但是目前stable diffusion代表的图像生成,倒是第一个如此贴近大众生活的应用,很有成为UGC工具的潜力。
欢迎关注我的公众号“言木木的佳常菜” 相关文章会在公众号第一时间发布,知乎同步更新~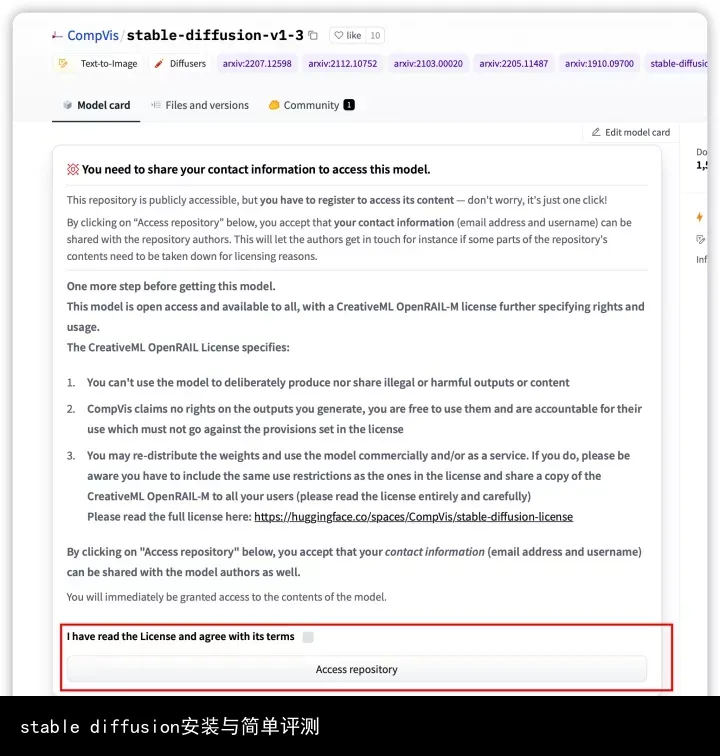
转载请注明:stable diffusion安装与简单评测 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号