潜在扩散模型 | AIGC| Diffusion Model
图片感知压缩 | GAN | Stable Diffusion
随着生成型AI技术的能力提升,越来越多的注意力放在了通过AI模型提升研发效率上。业内比较火的AI模型有很多,比如画图神器Midjourney、用途多样的Stable Diffusion,以及OpenAI此前刚刚迭代的DALL-E 2。
对于研发团队而言,尽管Midjourney功能强大且不需要本地安装,但它对于硬件性能的要求较高,甚至同一个指令每次得到的结果都不尽相同。相对而言,Stable Diffusion因具备功能多、开源、运行速度快,且能耗低内存占用小成为更理想的选择。

AIGC和ChatGPT4技术的爆燃和狂飙,让文字生成、音频生成、图像生成、视频生成、策略生成、GAMEAI、虚拟人等生成领域得到了极大的提升。不仅可以提高创作质量,还能降低成本,增加效率。同时,对GPU和算力的需求也越来越高,因此GPU服务器厂商开始涌向该赛道,为这一领域提供更好的支持。
本文将重点从Stable Diffusion如何安装、Stable Diffusion工作原理及Diffusion model与GAN相比的优劣势为大家展开详细介绍。
Stable Diffusion如何安装
Stable Diffusion是一个非常有用的工具,可以帮助用户快速、准确地生成想要的场景及图片。它的安装也非常简单,只需要按照上述步骤进行即可。如果您需要快速生成图片及场景,Stable Diffusion是一个值得尝试的工具。
一、环境准备
1、硬件方面
4G起步,4G显存支持生成512*512大小图片,超过这个大小将卡爆失败。这里小编建议使用RTX 3090。
2)硬盘
10G起步,模型基本都在5G以上,有个30G硬盘不为过吧?现在硬盘容量应该不是个问题。
2、软件方面
1)Git
https://git-scm.com/download/win
下载最新版即可,对版本没有要求。
2)Python
https://www.python.org/downloads/
3)Nvidia CUDA
https://developer.download.nvidia.cn/compute/cuda/11.7.1/local_installers/cuda_11.7.1_516.94_windows.exe
版本11.7.1,搭配Nvidia驱动516.94,可使用最新版。
4)stable-diffusion-webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui
核心部件当然用最新版本~~但注意上面三个的版本的兼容性。
5)中文语言包
https://github.com/VinsonLaro/stable-diffusion-webui-chinese
下载chinese-all-0306.json 和 chinese-english-0306.json文件
6)扩展(可选)
https://github.com/Mikubill/sd-webui-controlnet
下载整个sd-webui-controlnet压缩包
https://huggingface.co/Hetaneko/Controlnet-models/tree/main/controlnet_safetensors
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
https://huggingface.co/TencentARC/T2I-Adapter/tree/main
试用时先下载第一个链接中的control_openpose.safetensors 或 第二个链接中的control_sd15_openpose.pth文件
7)模型
https://huggingface.co/models
https://civitai.com
可以网上去找推荐的一些模型,一般后缀名为ckpt、pt、pth、safetensors ,有时也会附带VAE(.vae.pt)或配置文件(.yaml)。
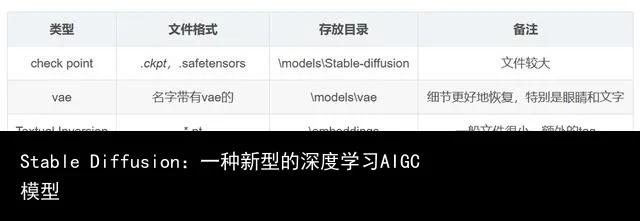
二、安装流程
1)安装Git
就正常安装,无问题。
2)安装Python
建议安装在非program files、非C盘目录,以防出现目录权限问题。
注意安装时勾选Add Python to PATH,这样可以在安装时自动加入windows环境变量PATH所需的Python路径。
3)安装Nvidia CUDA
正常安装,无问题。
4)安装stable-diffusion-webui
国内需要用到代理和镜像,请按照下面的步骤操作:
a) 编辑根目录下launch.py文件
将https://github.com替换为https://ghproxy.com/https://github.com,即使用Ghproxy代理,加速国内Git。
b) 执行根目录下webui.bat文件
根目录下将生成tmp和venv目录。
c) 编辑venv目录下pyvenv.cfg文件
将include-system-site-packages = false改为include-system-site-packages = true。
d) 配置python库管理器pip
方便起见,在\venv\Scripts下打开cmd后执行如下命令:

xformer会安装到\venv\Lib\site-packages中,安装失败可以用pip install -U xformers命试试。
e) 安装语言包
将文件chinese-all-0306.json 和 chinese-english-0306.json放到目录\localizations目录中。运行webui后进行配置,操作方法见下。
f) 安装扩展(可选)
将sd-webui-controlnet解压缩到\extensions目录中。将control_sd15_openpose.pth文件复制到/extensions/sd-webui-controlnet/models目录中。不同的扩展可能还需要安装对应的系统,比如controlnet要正常使用则还需要安装ffmpeg等。
g) 安装模型
下载的各种模型放在\models\Stable-diffusion目录中即可。
h) 再次执行根目录下webui.bat文件
用浏览器打开webui.bat所提供的网址即可运行。
其中提供了网址:http://127.0.0.1:7860。
打开该网址后在Settings -> User interface -> Localization (requires restart)设置语言,在菜单中选择chinese-all-0220(前提是已经在目录中放入了对应语言包,见上),点击Apply Settings确定,并且点击Reload UI重启界面后即可。
Stable Diffusion背后的原理
Latent Diffusion Models(潜在扩散模型)的整体框架如下图所示。首先需要训练一个自编码模型,这样就可以利用编码器对图片进行压缩,然后在潜在表示空间上进行扩散操作,最后再用解码器恢复到原始像素空间。这种方法被称为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易地推广到文本、音频、视频等领域
在潜在表示空间上进行diffusion操作的主要过程和标准的扩散模型没有太大的区别,所使用的扩散模型的具体实现为time-conditional UNet。但是,论文为扩散操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
下面我们针对感知压缩、扩散模型、条件机制的具体细节进行展开。
一、图片感知压缩(Perceptual Image Compression)
感知压缩本质上是一个tradeoff。之前的许多扩散模型没有使用这种技术也可以进行,但是原有的非感知压缩的扩散模型存在一个很大的问题,即在像素空间上训练模型时,如果希望生成高分辨率的图像,则训练空间也是高维的。感知压缩通过使用自编码模型,忽略高频信息,只保留重要的基础特征,从而大幅降低训练和采样阶段的计算复杂度,使文图生成等任务能够在消费级GPU上在10秒内生成图片,降低了落地门槛。
感知压缩利用预训练的自编码模型,学习到一个在感知上等同于图像空间的潜在表示空间。这种方法的优势在于,只需要训练一个通用的自编码模型,就可以用于不同的扩散模型的训练,在不同的任务上使用。
因此,基于感知压缩的扩散模型的训练本质上是一个两阶段训练的过程,第一阶段需要训练一个自编码器,第二阶段才需要训练扩散模型本身。在第一阶段训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种实现。
二、潜在扩散模型(Latent Diffusion Models)
首先简要介绍一下普通的扩散模型(DM),扩散模型可以解释为一个时序去噪自编码器(equally weighted sequence of denoising autoencoders),其目标是根据输入
去预测一个对应去噪后的变体,或者说预测噪音,其中
是输入的噪音版本。相应的目标函数可以写成如下形式:

其中从

中均匀采样获得。
而在潜在扩散模型中,引入了预训练的感知压缩模型,它包括一个编码器
和一个解码器
。这样就可以利用在训练时就可以利用编码器得到
,从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式:
三、条件机制
除了无条件图片生成外,我们也可以进行条件图片生成,这主要是通过拓展得到一个条件时序去噪自编码器(conditional denoising autoencoder)
来实现的,这样一来我们就可通过
来控制图片合成的过程。具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现
。为了能够从多个不同的模态预处理
,论文引入了一个领域专用编码器(domain specific encoder)
,它用来将
映射为一个中间表示
,这样我们就可以很方便的引入各种形态的条件(文本、类别、layout等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:
其中
是UNet的一个中间表征。相应的目标函数可以写成如下形式:
四、效率与效果的权衡
分析不同下采样因子f∈{1,2,4,8,16,32}(简称LDM-f,其中LDM-1对应基于像素的DMs)的效果。为了获得可比较的测试结果,固定在一个NVIDIA A100上进行了实验,并使用相同数量的步骤和参数训练模型。实验结果表明,LDM-{1,2}这样的小下采样因子训练缓慢,因为它将大部分感知压缩留给扩散模型。而f值过大,则导致在相对较少的训练步骤后保真度停滞不前,原因在于第一阶段压缩过多,导致信息丢失,从而限制了可达到的质量。LDM-{4-16}在效率和感知结果之间取得了较好的平衡。与基于像素的LDM-1相比,LDM-{4-8}实现了更低的FID得分,同时显著提高了样本吞吐量。对于像ImageNet这样的复杂数据集,需要降低压缩率以避免降低质量。总之,LDM-4和-8提供了较高质量的合成结果。
Diffusion model与GAN相比的优劣势
一、优点
Diffusion Model相比于GAN,明显的优点是避免了麻烦的对抗学习。此外,还有几个不太明显的好处:首先,Diffusion Model可以“完美”用latent去表示图片,因为我们可以用一个ODE从latent变到图片,同一个ODE反过来就可以从图片变到latent。而GAN很难找到真实图片对应什么latent,所以可能会不太好修改非GAN生成的图片。其次,Diffusion Model可以用来做“基于色块的编辑”(SDEdit),而GAN没有这样的性质,所以效果会差很多。再次,由于Diffusion Model和score之间的联系,它可以用来做inverse problem solver的learned prior,例如我有一个清晰图片的生成模型,看到一个模糊图片,可以用生成模型作为先验让图片更清晰。最后,Diffusion Model可以求model likelihood,而这个GAN就很难办。Diffusion Model最近的流行一部分也可能是因为GAN卷不太动了。虽然严格意义上说,Diffusion Model最早出自Jascha Sohl-Dickstein在ICML 2015就发表的文章,和GAN的NeurIPS 2014也差不了多少;不过DCGAN/WGAN这种让GAN沃克的工作在2015-17就出了,而Diffusion Model在大家眼中做沃克基本上在NeurIPS 2020,所以最近看上去更火也正常。
二、不足之处
Diffusion model相比于GAN也存在一些缺陷。首先,无法直接修改潜在空间的维度,这意味着无法像StyleGAN中使用AdaIN对图像风格进行操作。其次,由于没有判别器,如果监督条件是“我想要网络输出的东西看起来像某个物体,但我不确定具体是什么”,就会比较困难。而GAN可以轻松地实现这一点,例如生成长颈鹿的图像。此外,由于需要迭代,生成速度比较慢,但在单纯的图像生成方面已经得到了解决。目前在条件图像生成方面的研究还不够充分,但可以尝试将Diffusion model应用于这一领域
转载请注明:Stable Diffusion:一种新型的深度学习AIGC模型 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号