我们大多数人都熟悉 Stable Diffusion 等 AI 图像生成器。然而,它远不止图像生成那么简单,我们可以在很多领域使用它们;
Stable Diffusion 是数学模型。而且,它们可以帮助你研究随时间变化的系统动态
它们基于扩散过程概念。因此,你可以检查范围广泛的现象。例如:热传递、化学反应和金融市场中的信息传播。
这些模型具有极强的适应性。所以,你可以根据一个系统的当前状况来预测它的未来状态
此外,你可以看到支配它的基本物理或金融原理。这个概念在许多领域都非常有用。这些领域包括物理学、化学和金融。
接下来我们来看看如何训练 Stable Diffusion 模型的教程。
它是如何诞生的?
这可以追溯到 19 世纪末。
物质扩散过程的数学研究是 Stable Diffusion 模型的起点。最流行的 Stable Diffusion 模型之一是 Fokker-Planck 方程。
它于 1906 年首次推出。这些模型随着时间的推移不断发展和修改。我们现在将它们用于各种行业。
背后的逻辑是什么?
正如我们所说,它是数学模型。此外,它帮助我们研究一个属性或数量是如何在一个系统中随时间扩散的。
它基于扩散过程的原理。帮助我们研究一个数量如何在一个系统中扩散。这种扩散是浓度、压力或其他参数变化的结果
让我们举一个简单的例子。想象一下,你有一个装满液体的容器,你在其中加入了一种染料。当染料开始在液体中分散和乳化时,这就是扩散。根据液体和染料的特性, Stable Diffusion 模型可以用来预测随着时间的推移染料如何分散和混合。
在更复杂的系统中,如金融市场或化学反应,这些模型可以预测信息或属性如何随着时间的推移传播和影响系统。此外,大量的数据可能被用来训练这些模型,以做出准确的预测。它们是使用描述系统长期演变的数学公式建立的。
了解和预测系统中某些性状在时间上的传播是这些模型的主要思想。重要的是要记住,专业领域的专家通常采用这些模型。
如何训练模型?
收集并准备好你的数据:
在开始训练模型之前,你必须首先收集和准备你的数据。你的数据可能需要被处理和格式化。另外,缺失的数字可能也需要被消除。
选择一个模型结构:
Stable Diffusion 模型有多种形式。它主要是基于福克-普朗克方程、薛定谔方程和马斯特方程。这些模型中的每一个都有其优势和劣势。选择最符合你的情况的模型即可。
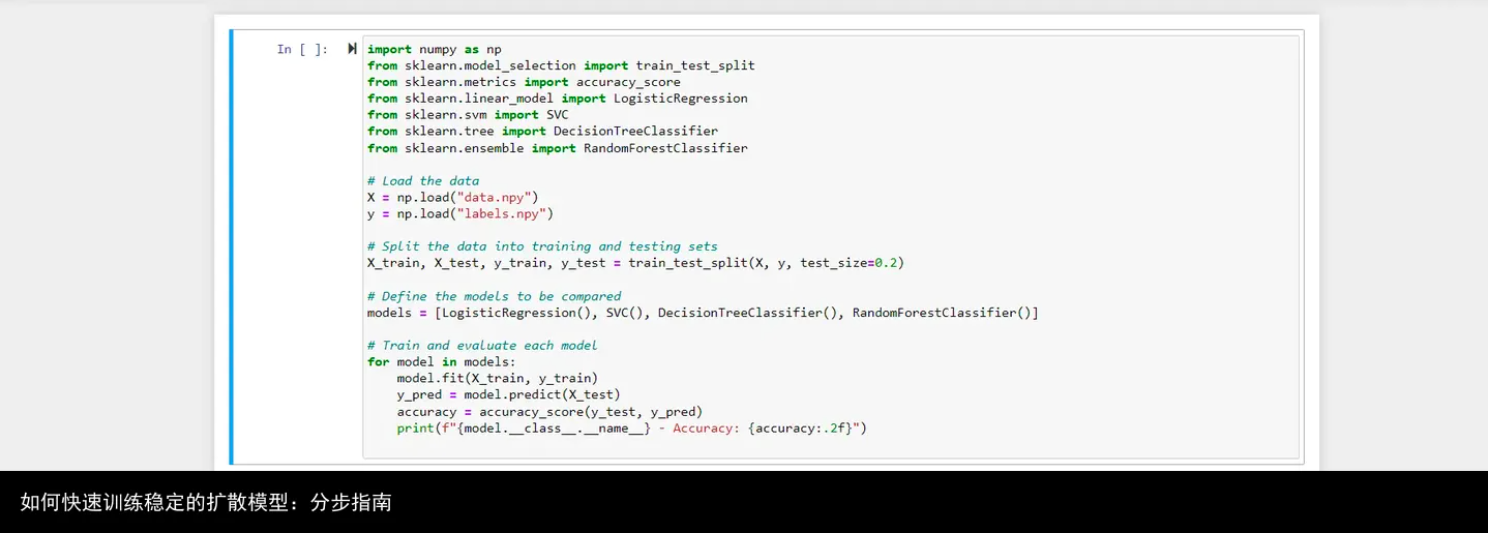
建立你的损失函数
这很重要,因为它影响到你的模型与数据的匹配程度。对于 Stable Diffusion 模型,平均平方误差和Kullback-Leibler发散是常用的损失函数。
训练你的模型
使用随机梯度下降或类似的优化方法,你可以在定义损失函数后开始训练你的模型。
检查你的模型的通用性
你应该在训练后通过与测试数据集的比较来检查新数据。
调整你的模型的超参数
为了提高模型的性能,可以试验各种超参数的值,如学习率、批量大小和网络中隐藏层的数量。
重复之前的操作
你可能需要重复这些过程不止一次,才能获得最佳结果。这将取决于问题的难度和数据的口径。
编码教程
Python、MATLAB、C++和R等编程语言都可以用来创建 Stable Diffusion 模型。所用的语言将取决于特定的应用。此外,它还取决于为该语言提供的工具和库。
在这种情况下,Python 是最好的选择。它有强大的库,如 NumPy 和 SciPy,用于数值计算。此外,它还支持TensorFlow 和 PyTorch 用于创建和训练神经网络。因此,它成为编写 Stable Diffusion 模型的一个伟大选择。
例子:
让我们使用扩散方程,这是一个数学公式,描述了一个质量或数量,如热量或物质的浓度,在一个系统中如何随时间变化。该方程一般是这样的:
∂u/∂t = α ∇²u
扩散系数()是对一个属性或数量在系统中传播的容易程度的测量。
u的拉普拉斯系数(2u)是对该属性或数量随空间变化的描述。其中u是被扩散的属性或数量(例如,温度或浓度),t是时间的推移,是扩散系数,是扩散常数()。
我们可以用Python中的 Euler 方法来实现它。
import numpy as np
# Define the diffusion coefficient
alpha = 0.1
# Define the initial condition (e.g. initial temperature or concentration)
u = np.ones(100)
# Time step
dt = 0.01
# Time-stepping loop
for t in range(1000):
# Compute the spatial derivative
du = np.diff(u)
# Update the value of u
u[1:] = u[1:] + alpha * du * dt
该代码使用 Euler 技术来实现扩散方程。它将起始状态描述为一个统一的初始条件,由一个形状为(100)的1的数组表示。0.01被用作时间步长。
时间步进循环的 1000 次迭代完成。
它使用 np.diff 函数,确定相邻元素之间的差异。因此,它计算出了被扩散的属性或数量的空间导数。而且,它在每次迭代时用 du 表示。
然后我们用空间导数乘以扩散系数α和时间步长来更新u的值。
一个更复杂的例子
一个只测量稳定热扩散的稳定扩散模型会是什么样子?该代码是如何运作的?
解决一组偏微分方程(PDEs)来解释热量如何随时间在系统中扩散是必要的。因此,我们可以训练一个 Stable Diffusion 模型来复制热量的稳定扩散。
下面是一个例子,说明如何用有限差分法解决热方程,这是一个解释热量在一维杆中稳定扩散的PDE:
import numpy as np
import matplotlib.pyplot as plt
# Define the initial conditions
L = 1 # length of the rod
Nx = 10 # number of spatial grid points
dx = L / (Nx - 1) # spatial grid spacing
dt = 0.01 # time step
T = 1 # total time
# Set up the spatial grid
x = np.linspace(0, L, Nx)
# Set up the initial temperature field
T0 = np.zeros(Nx)
T0[0] = 100 # left boundary condition
T0[-1] = 0 # right boundary condition
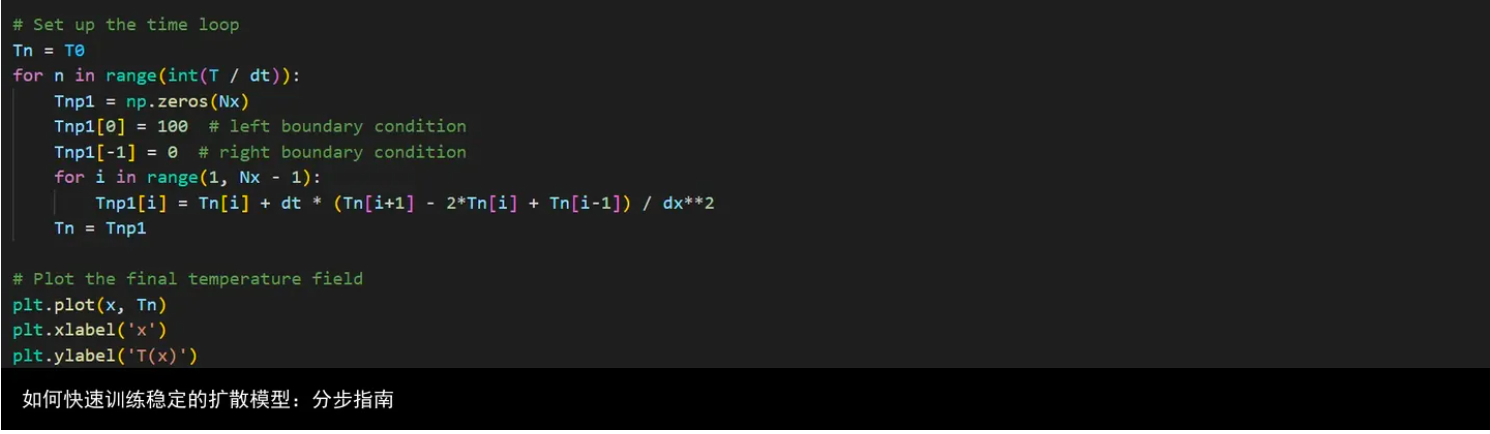
# Set up the time loop
Tn = T0
for n in range(int(T / dt)):
Tnp1 = np.zeros(Nx)
Tnp1[0] = 100 # left boundary condition
Tnp1[-1] = 0 # right boundary condition
for i in range(1, Nx - 1):
Tnp1[i] = Tn[i] + dt * (Tn[i+1] - 2*Tn[i] + Tn[i-1]) / dx**2
Tn = Tnp1
# Plot the final temperature field
plt.plot(x, Tn)
plt.xlabel(x)
plt.ylabel(T(x))
plt.show()
从文本生成图像是如何工作的?
由于它在互联网上相当流行,我们也可以看看图像生成是如何工作的。
自然语言处理(NLP)方法和神经网络。而且,它们经常被用来为文本到图像的转换提供一个 Stable Diffusion 模型。以下是对如何完成的大致描述:
1- 对文本数据中的单词进行标记,并消除停止词和标点符号。将这些词变成数值。这是预处理的一部分(词嵌入)。
import nltk
from nltk.tokenize import word_tokenize
nltk.download(punkt)
# Pre-processing the text data
text = "a bird sitting on a flower. "
words = word_tokenize(text)
words = [word.lower() for word in words if word.isalpha()]
2- 学习如何使用一个结合了编码器和解码器的神经网络将文本和图像联系起来。解码器网络接收潜伏代码作为输入。然后,在编码器网络将文本数据转换为紧凑的表示方式(潜伏代码)后,它创建相关图片。
import tensorflow as tf
# Define the encoder model
encoder = tf.keras.Sequential()
encoder.add(tf.keras.layers.Embedding(input_dim=vocab_size,
output_dim=latent_dim))
encoder.add(tf.keras.layers.GRU(latent_dim))
encoder.add(tf.keras.layers.Dense(latent_dim))
# Define the decoder model
decoder = tf.keras.Sequential()
decoder.add(tf.keras.layers.Dense(latent_dim,
input_shape=(latent_dim,)))
decoder.add(tf.keras.layers.GRU(latent_dim))
decoder.add(tf.keras.layers.Dense(vocab_size))
# Combine the encoder and decoder into an end-to-end model
model = tf.keras.Sequential([encoder, decoder])
3- 通过向它提供大量的图像和与之配套的文字描述。然后,你可以训练编码器-解码器网络。
# Compile the model
model.compile(optimizer=adam,
loss=categorical_crossentropy)
# Train the model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=32)
4- 在网络训练完成后,你可以用它从新鲜的文本输入中产生图片。而且,它是通过将文本输入编码器网络。然后,你可以产生一个潜伏代码,然后将潜伏代码送入解码器网络以产生相关的图像。
# Encode the text input
latent_code = encoder.predict(text)
# Generate an image from the latent code
image = decoder.predict(latent_code)
5-选择适当的数据集和损失函数是最关键的步骤之一。数据集是多种多样的,包含各种各样的图片和文字描述。我们要确保这些图片是真实的。同时,我们需要确定文本描述是可行的,这样我们才能设计损失函数。
# Define the loss function
loss = tf.losses.mean_squared_error(y_true, y_pred)
# Compile the model
model.compile(optimizer=adam, loss=loss)
# use diverse dataset
from sklearn.utils import shuffle
X_train, y_train = shuffle(X_train, y_train)
最后,你可以尝试使用其他架构和方法。这样,你可以提高模型的性能,如注意机制、GANs或VAEs。
转载请注明:如何快速训练稳定的扩散模型:分步指南 | GO123.AI网址大全 | ChatGPT | Midjourney | Stable Diffusion | AI工具软件 | AI软件免费教程
相关文章

 京公网安备 11010502044423号
京公网安备 11010502044423号