












为了提高模型性能,来自斯坦福的研究者帮助其完成了指令微调的工作,训练了一个名为 Alpaca(羊驼)的 70 亿参数新模型(基于 LLaMA 7B)。具体来说,他们让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。实验结果表明,Alpaca 的很多行为都与 text-davinci-003 类似。也就是说,只有 7B 参数的轻量级模型 Alpaca 性能可媲美 GPT-3.5 这样的超大规模语言模型。

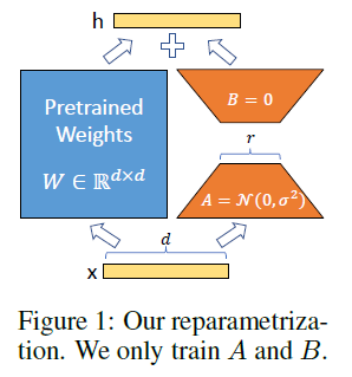
开源地址:GitHub - tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware
相关导航





GO123.AI网址大全是猎户星空旗下的一款收集流行AI应用网址的平台,提供AI作图、聊天、视频编辑等资源。我们还提供ChatGPT的新手教程和高级玩法指导,为用户提供最全面、最实用的服务。欢迎来猎户星空旗下的GO123.AI网址大全,一起探索AI应用的无限可能!

 京公网安备 11010502044423号
京公网安备 11010502044423号